

8. Text processing
8.1 Data information
Below is sentiment dictionary sentiment_lexicon.csv:
| Field | Description |
|---|---|
| Word | Words |
| Sentiment_Score | Emotion scores: positive emotions with a maximum score of 5 and negative emotions with a minimum score of -5. |
8.2 Find high-frequency words in customer feedback
Step 1: Data retrieval, during which all characters in the feedback are unified into lowercase and whitespace characters at both ends are removed.
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc(customer,feedBack) |
| 2 | =A1.run(feedBack=trim(lower(feedBack))) |
Below is result of executing A1’s statement:
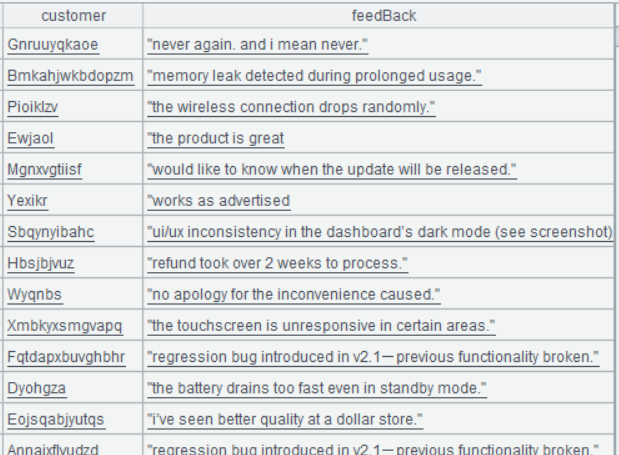
A2 trim()function removes whitespace characters at both ends of characters. lower() function converts strings into lowercase.
Below is result of executing A2’s statement:
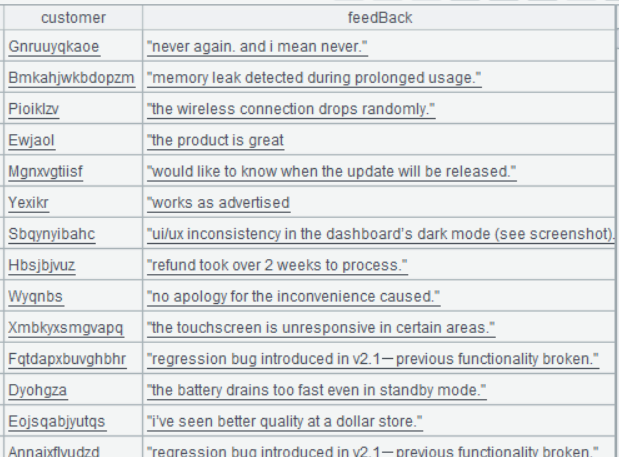
Step 2: Transform the feedback information into a sequence of words, group it by word and count the frequencies of each word.
| A | |
|---|---|
| 3 | =A2.conj(feedBack.words()) |
| 4 | =A3.groups(~:value;count(1):Count) |
| 5 | =A4.sort(-Count) |
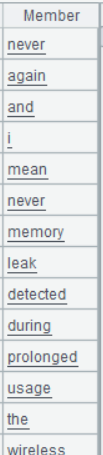
A3 feedBack.words()transforms feedback into sequences of words; conj() function concatenates sequences into a larger sequence.
Below is result of executing A3’s statement:
A4 Group A3 by word and count the number of each word’s appearances.
Below is result of executing A4’s statement:
A5 Sort records by word frequency count in descending order, putting those with the highest frequency count at the beginning.
Below is result of executing A5’s statement:
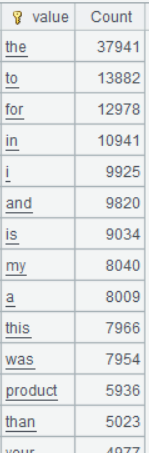
Step 3: Remove meaningless words.
In A5’s result, there are a large number of words that are insignificant in business, including prepositions, conjunctions and definite articles. And they need to be removed:
| A | |
|---|---|
| 6 | [the,to,for,in,i,and,is,my,a,this,was,than,as,after,no,you,would,s,by,never,of,with,up,me,during,it,t,be,on,will,even,please,d,v,or,your] |
| 7 | =A6.sort() |
| 8 | =A5.select(!A7.contain@b(value)) |
A8 Select records of A5 whose values are not included in A7. @b option in A7.contain@b(value) enables to use more efficient binary search to locate the target records when A7 is ordered by value field.
Below is result of executing A8’s statement:
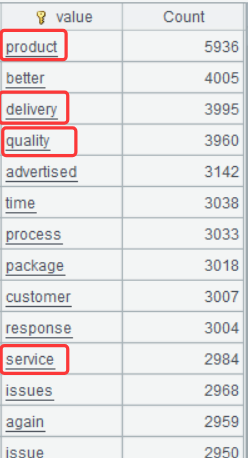
A result set without the meaningless words becomes clearer and highlights the core issues customers care about – products, quality, service and delivery, enabling businesses to accurately identify business dimensions that customers most concern about.
8.3 Customer satisfaction analysis
To find whether customers satisfied with the product or not, we can perform the sentiment analysis. Here let’s implement a simple, dictionary-based method:
Step 1: Import customer names and feedbacks from the sales data, organize the feedback data and convert it to sequence of words. The code is the same as that in the preceding example.
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc(customer,feedBack) |
| 2 | =A1.run(feedBack=trim(lower(feedBack))) |
| 3 | =A2.derive(feedBack.words():Words) |
A3 Convert feedBack data to sequences of words and store them in a newly-added field named Words.
Below is result of executing A3’s statement:
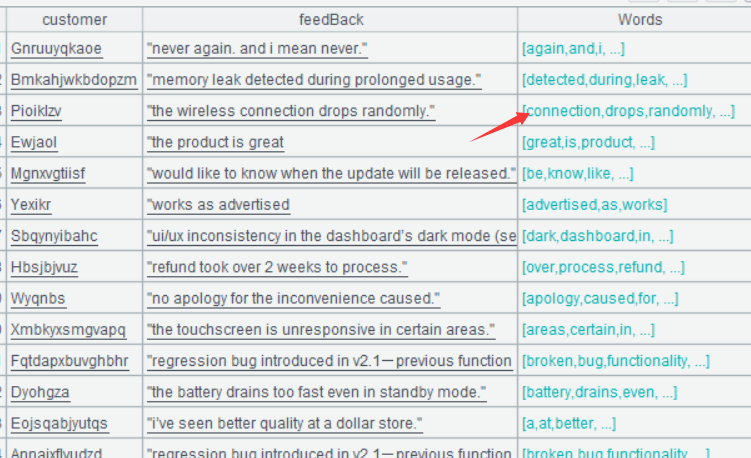
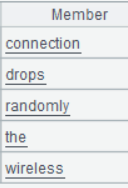
Double-click the Words field value in any row and the following will be displayed:
Step 2: Import data from the sentiment dictionary
| A | |
|---|---|
| 4 | =file(“sentiment_lexicon.csv”).import@ct() |
Below is result of executing A4’s statement:
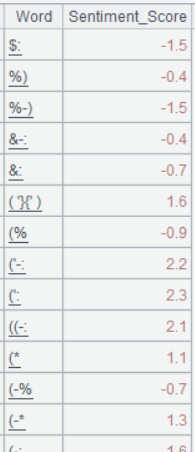
Step 3: Create association between the sentiment dictionary and the sequence of feedback words, and compute the average sentiment score.
| A | |
|---|---|
| 5 | =A3.derive(A4.align@b(Words:~,Word).avg(ifn(~.Sentiment_Score,0)):Sentiment_Score) |
A5 Meaning of A4.align@b(Words:~,Word): Create association between A4 and Words field according to the current member of sequence Words and A4’s Word field value. .avg(ifn(~.Sentiment_Score,0)) computes average on the joining result; in the expression, ifn(~.Sentiment_Score,0) means getting 0 if ~.Sentiment_Score is null, as some words may not exist in the dictionary.
Below is result of executing A5’s statement:
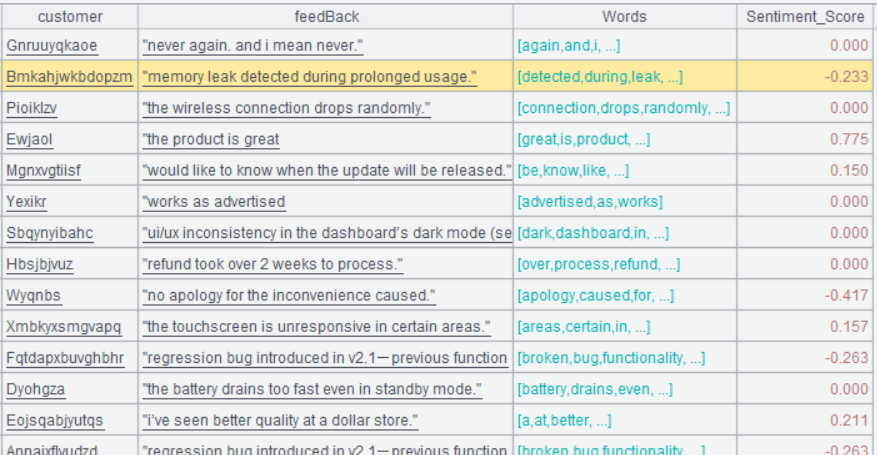
Step 4: Grade customer sentiment scores.
| A | |
|---|---|
| 6 | =A5.derive(if(Sentiment_Score>0.2:“positive”,Sentiment_Score<-0.2:“negative”;“neutral”): Sentiment) |
A6 Scores greater than 0.2 is considered positive, those less than 0.2 is considered negative, and the others are considered neutral.
Below is result of executing A6’s statement:
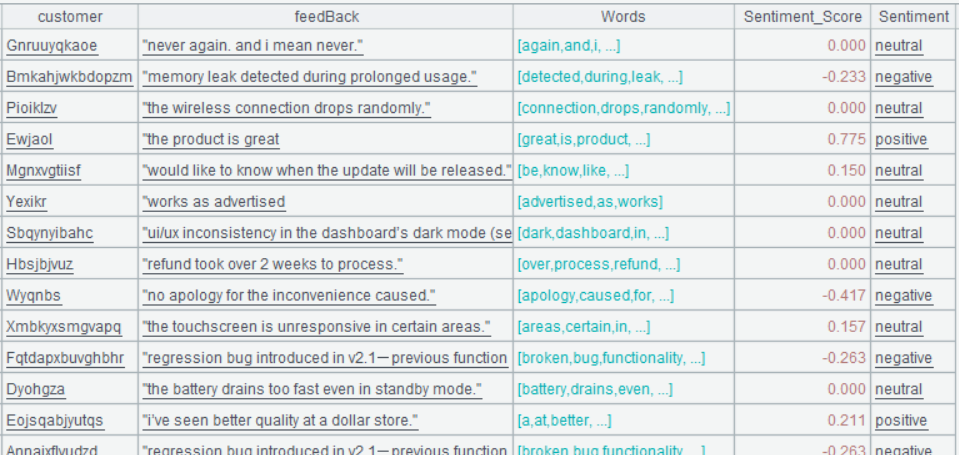
The analysis gives a quick customer emotional landscape. Through it you may find these:
- 65% of the feedback is positive, 20% of it is negative, and 15% is neutral.
- Certain products have obviously more negative feedback than others.
- Feedback of customers in certain regions are usually more positive.
- Customer emotions become more positive as time goes by.
Theses insights can help you:
- Identify areas that need improvement;
- Track product & service optimization effect.
8.4 Finding topics customers most concern about
Besides sentiment inclinations, you may want to learn about the specific topics customers concern about. Let’s implement a simple topic classification method based on keywords.
Step 1: Import customer names and feedbacks from the sales data, organize the feedback data and convert it to sequence of words. The code is the same as that in the preceding example.
| A | |
|---|---|
| 1 | =file(“sales.csv”).import@tc(customer,feedBack) |
| 2 | =A1.run(feedBack=trim(lower(feedBack))) |
| 3 | =A2.derive(feedBack.words().sort():Words) |
Step 2: Generate a simple topic vocabulary table.
| A | |
|---|---|
| 4 | =[[“price”,“cost”,“expensive”,“cheap”,“affordable”,“fees”,“cheaper”,“charged”,“refund”,“money”,“worth”,“penny”,“buy”,“lower”,“higher”,“overpriced”,], [“quality”,“durable”,“broke”,“lasting”,“sturdy”,“drops”,“randomly”,“drains”,“interface”,“leak”,“error”,“inconsistency”,“slower”,“freezes”,“resetting”,“overheats”,“compatibility”,“unresponsive”], [“service”,“support”,“help”,“response”,“staff”,“update”,“released”,“process”,“apology”,“inconvenience”,“patience”,“delivery”,“waited”,“rude”,“follow”,“available”,“late”]] |
| 5 | = [“price”,“quality”,“service”] |
| 6 | =A4.new(~.sort():Keys, A5(A4.#):Topics) |
Below is result of executing A6’s statement:
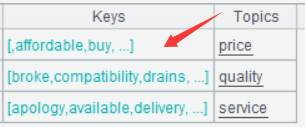
Double-click Keys field of one of the rows and the following will be displayed:
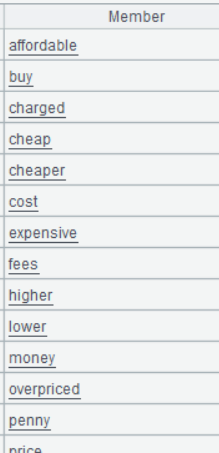
Step 3: Search A6 for Topics value matching each Words value in A3. Since A3’s Words value is a sequence of words, maybe multiple topics will match it.
| A | |
|---|---|
| 7 | =A3.derive(Words.(A6.select@1(Keys.contain@b(Words.~)).Topics):topic_matches) |
A7 Meaning of select@1: Stop the search once a record meeting the specified condition is found.
Below is result of executing A7’s statement:
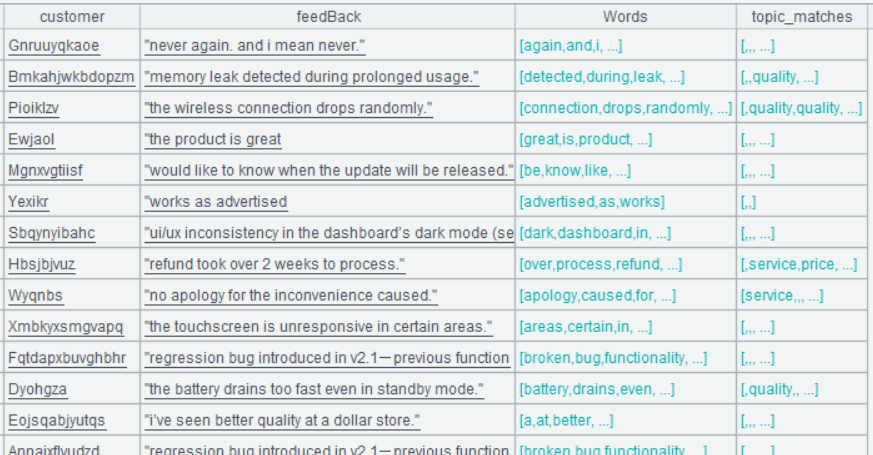
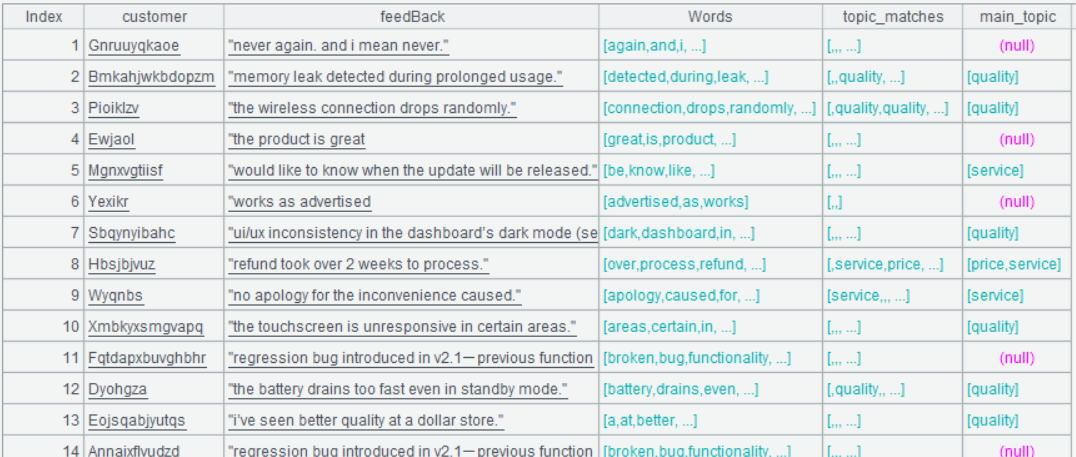
Step 4: Find the most frequently appeared topic among topic_matches values and make it the main_topic.
| A | |
|---|---|
| 8 | =A7.derive(topic_matches.select(~).groups(~:topics;count(1):c).maxp@a(c).id(topics):main_topic) |
A8 Meaning of @a option in maxp@a: If there are tied values for the maximum, get both of them.
Below is result of executing A8’s statement:
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL

