

SPL Lightweight Multisource Mixed Computation Practices
0 Preparation
Background
Multiple or diverse-source mixed computations are common needs. They may occur between different types of databases, between files and databases, and between NoSQL databases and files. Theoretically, such computations and analyses might exist between any data storages. The now known technologies cannot handle mixed computations well, even satisfactorily. Though some database products support mixed computations between same-type databases, it is difficult to perform those computations between completely different types of data sources. Logical data warehouses can implement the multi/diverse-source mixed computations to some extent because most of them are SQL-based and thus can access RDB data sources through table mapping. Accesses to the other types of data sources become hard, and data virtualization, which is complex, is needed. But even so not all data sources can be accessed. Moreover, logical data warehouse architecture is so heavy that usually it is even more complicated than the application itself. They only suit large-scale computing scenarios.
esProc SPL supports a rich variety of data sources, which, once successfully connected, will be transformed to uniform data objects (table sequence or cursor), laying the natural foundation for mixed computations between any data sources, as long as they can be accessed by SPL. Being very lightweight, SPL can be embedded in an application and equip the latter with the multi/diverse-source mixed computation ability. Moreover, SPL even outstrips SQL with its succinct syntax. Using SPL to perform multisource mixed computations brings both computing ability and convenient engineering implementation.
SPL provides different connectors for different data sources. Below is the SPL-led computing architecture:
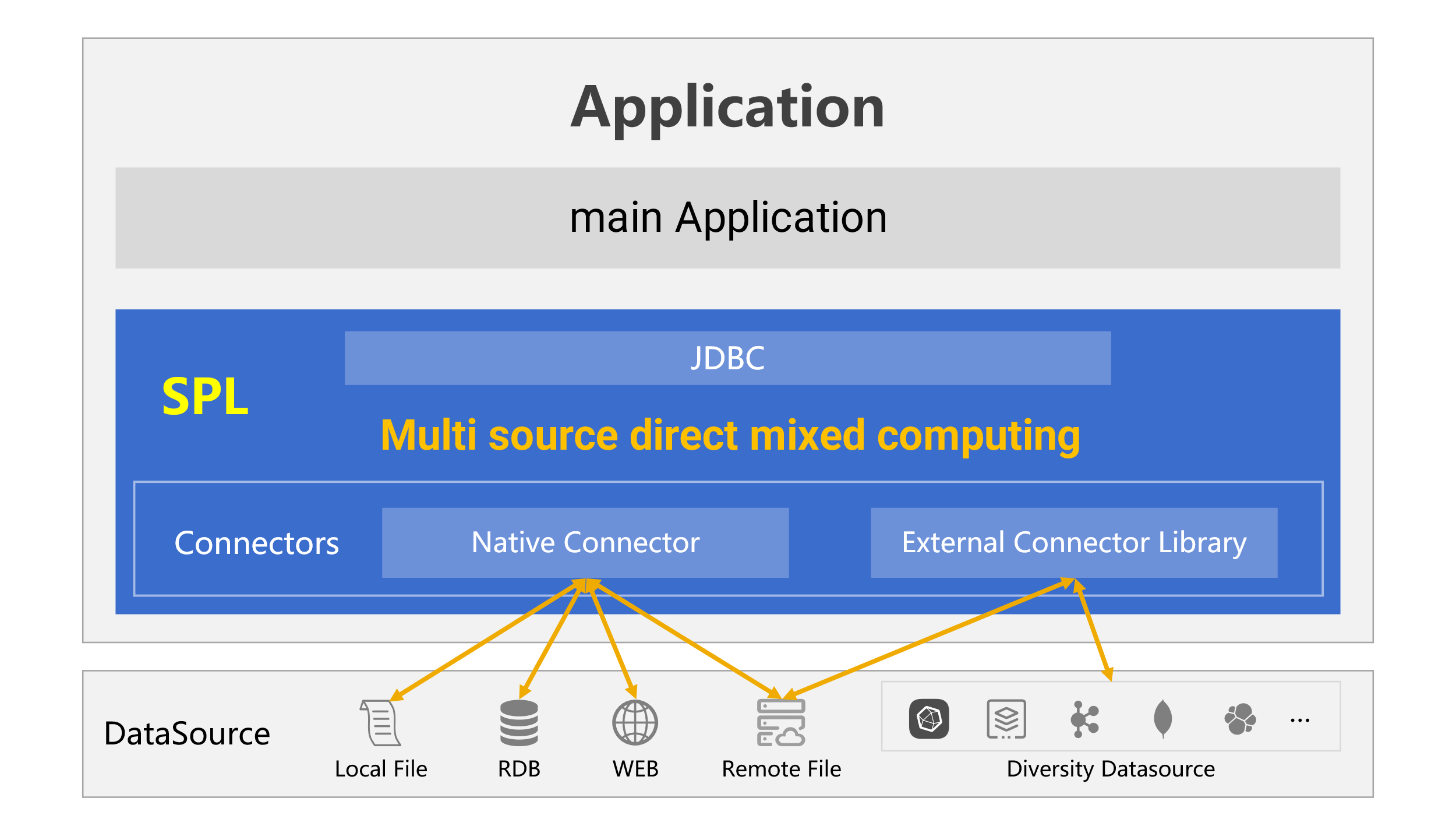
There are two types of SPL data source connectors – native and external. Native connectors are built as SPL’s core components. They include the most commonly seen RDBs, local files such as text, Excel and JSON, and the HTTP source. Various other data sources, such as MongoDB, Kafka, ElasticSearch and cloud storages, are external connectors, which are not SPL core components and need to be specifically deployed.
Below is a list of commonly used data sources SPL supports:

SPL native connectors support accessing JDBC data sources such as MySQL and Oracle, local files such as CSV, Excel and JSON, Web data sources such as HTTP and RestAPI, remote files, and other sources.
Our discussion about SPL multisource mixed computations will cover the following parts:
Contents
Practices #1: Running SQL in RDBs
Learn basic use of SPL, how SPL interacts with the database, and how to integrate SPL with the application.
Practices #2: Querying CSV/XLS and other files
Learn to use native SPL syntax and SQL syntax to query, process and analyze data from file sources.
Practices #3: Querying Restful/JSON data
Learn to process multilevel data with SPL.
Practices #4: Querying MongoDB
Learn to connect to and query data from external data sources (Use MongoDB as the example).
Practices #5: Cross-datasource union and comparison
Learn to use SPL to perform cross-datasource union and distinct operations, and meanwhile perform data comparison; learn SPL big data processing methods.
Practice #6: Cross-datasource JOIN
Learn to perform cross-datasource join on different formats of data, and understand advantages of SPL’s categorizing JOIN operations; learn to deal with big table joins.
Practice #7: SQL migration
Learn to use SPL to solve SQL database migration problem – keep original SQL when performing migration between different databases.
Prepare environment
esProc SPL
Download and install esProc SPL Standard Edition .
Databases
MySQL
Download and install MySQL.
MongoDB
Install and configure MySQL.
Download data files
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese vesion