

8. Using cursor on large data sets
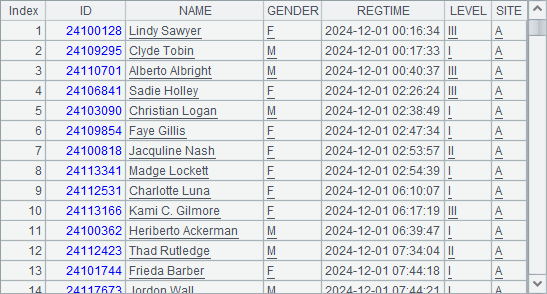
RegisterSiteA.csv stores a large volume of exam registration information ordered by registration time REGTIME. (1) Get the first 100 registration records; (2) Find how many people registered on the day of December 3, 2024; (3) Get registration records of the applicants whose ID values fall within the first 100; and (4) If different applicants have different IDs, check whether there are applicants who sign up repeatedly.
Expected results:
SPL code:
| A | B | |
|---|---|---|
| 1 | =file(“RegisterSiteA.csv”).cursor@ct() | =A1.fetch(100) |
| 2 | >A1.reset() | 2024-12-3 |
| 3 | =A1.skip(;date(REGTIME)!=B2) | =A1.fetch@x(;date(REGTIME)) |
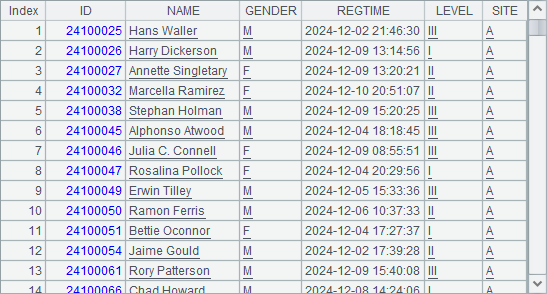
| 4 | =file(“RegisterSiteA.csv”).cursor@ct().sortx(ID) | =A4.fetch@x(100) |
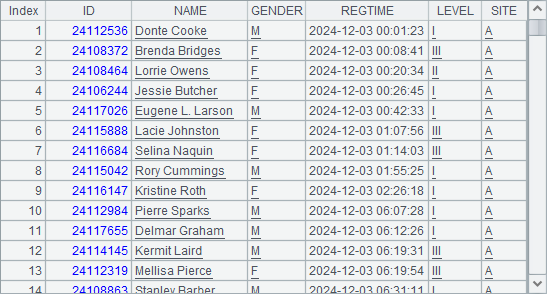
| 5 | =file(“RegisterSiteA.csv”).cursor@ct() | =A5.skip() |
| 6 | >A5.reset() | =A5.groups(;icount(ID):IDS) |
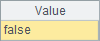
| 7 | =B5>B6.IDS |
A1 creates a cursor based on the data file. It uses @ct options because the data file is comma-separated csv file and the first line will be imported as column headers. In B1, fetch()function specifies the number of records to be returned and returns the result A1 expects. As a cursor traverses data only once, A2 uses cs.reset() function to turn it back to perform the next data query. In A3’s cs.skip(;x) function, the parameter after the semicolon does not specifiy the number of records to be skipped; instead it specifies a condition by which records not meeting it will be skipped. Now B3 continues to query data with the cursor starting from the current position. cs.fetch(;x) function fetches records until value of parameter x – date value – changes, and it works with @x option to close the cursor when data retrieval is finished.
A4 re-creates a cursor. As the data file is ordered by REGTIME instead of ID, cs.sortx()is used to perform a sorting in the buffer when data is retrieved with the cursor. Then B4 uses fetch() function to fetch data from the cursor and returns the sorting result.
A5 creates a cursor anew. B5 skip all records with skip()function and returns the actual number of records skipped. A6 turns the cursor back, and B6 uses groups() function to group and summarize data in the cursor. As no grouping expression is specified, groups()function will summarize all data. icount() function counts the number of distinct values. Here are results of B5 and B6:

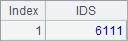
B5’s result is a numeric value. B6’s result is a table sequence having one record. The two values are same. This means that there are no repeat registrations.
9. Cursor merge
Contents and Exercise Data
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version