

When AI-Generated SQL Becomes Untrustworthy: How to Restore Confidence in Our Data
A growing trust crisis
You throw a task at an AI, and seconds later it spits out a dozen-line SQL blob. You copy and paste it, and it runs. But do you really feel confident about it?
That’s probably the daily reality for every data analyst and developer today.
Today, AI can generate runnable SQL. The problem is that you don’t know whether you can trust it. Once queries involve deeply nested window functions and multi-level subqueries, they become difficult to review, debug, maintain, and port across databases.
Research has shown that when LLMs lack sufficient schema context and domain knowledge, they can produce hallucinated outputs, such as incorrect table joins, flawed aggregation logic, or missing critical filters. According to dbt’s 2026 benchmark, even the most advanced LLMs achieved only 64.5% accuracy on Text2SQL tasks. In other words, one out of every three SQL queries generated by AI may contain errors.
A 2025 Stack Overflow survey revealed a more unsettling fact: only 2.7% of professional developers place a high level of trust in AI tools. Meanwhile, 42% of submitted code is already AI-generated, and only 48% of is reviewed by humans. The latest GitHub data paints a worrying picture: AI is rapidly producing code, while humans are struggling to keep up with the pace of verification.
Is this an AI problem, or a problem of how we approach it?
If you think about it, the root of the problem may not lie in AI itself, but in the fact that we are asking AI to do things it is not well suited for.
AI is well suited for brainstorming. It can help you clarify your thinking, break down complex requirements, and explore multiple possible solutions. However, when it comes to precise execution, the statistical nature of AI means it cannot guarantee a 100% correct result.
Entrusting final code generation to a probabilistic model is, in itself, a methodological mismatch.
The decline of Stack Overflow indirectly confirms this point. The number of new questions on this platform — once a hub of knowledge for developers worldwide — plummeted from a peak of over 300,000 per month to just 2,640 in January 2026. Developers have increasingly turned to AI for quick answers, only to find that the results inconsistent and unreliable.
Thus, we are stuck in an awkward situation: we use AI to improve efficiency, only to find that we cannot fully trust it.
Is there a way to combine AI’s flexibility with our need for certainty?
SQLazy: Let AI think, let the compiler write
This is the original intention behind SQLazy: implement complex SQL logic step by step using natural language, then compile it into auditable, production-ready SQL.
SQLazy’s core idea is simple yet unconventional: do not let AI generate the final SQL directly. Instead, you – or an AI assistant – breaks down complex requirements into clear, step-by-step logic. That logic is then passed to a deterministic compiler, which generates the final executable SQL.
Let’s make this approach clearer with an analogy: AI is your advisor, helping you map out the strategy; the compiler is your craftsman, turning that logic into a product through a deterministic workflow. You are responsible for verifying the soundness of the reasoning throughout the workflow, while the machine handles the execution details – much like using a calculator for arithmetic: you input the correct sequence of operations, and it guarantees the correct result.
Example: Grouping based on adjacent record comparison
In the following event table ordered by timestamp, some adjacent rows have identical values in the “value” field.
id |
value |
timestamp |
1 |
1 |
2023-11-10 13:00:00 |
2 |
2 |
2023-11-11 13:00:00 |
3 |
2 |
2023-11-12 13:00:00 |
4 |
1 |
2023-11-13 13:00:00 |
5 |
1 |
2023-11-14 13:00:00 |
6 |
1 |
2023-11-15 13:00:00 |
7 |
2 |
2023-11-16 13:00:00 |
8 |
2 |
2023-11-17 13:00:00 |
9 |
1 |
2023-11-18 13:00:00 |
We want to put adjacent records with the same value in one group. For each group, take the group’s start timestamp and the start timestamp of the next group as its start and end timestamps, and use them to construct a new two-dimensional table. For the last group, the start timestamp of the next group is defined as 9999-12-31 00:00:00.
id |
value |
effective_from |
effective_to |
1 |
1 |
2023-11-10 13:00:00 |
2023-11-11 13:00:00 |
2 |
2 |
2023-11-11 13:00:00 |
2023-11-13 13:00:00 |
4 |
1 |
2023-11-13 13:00:00 |
2023-11-16 13:00:00 |
7 |
2 |
2023-11-16 13:00:00 |
2023-11-18 13:00:00 |
9 |
1 |
2023-11-18 13:00:00 |
9999-12-31 00:00:00 |
Writing SQL is not easy. Let’s try solving it step by step with SQLazy:
Name |
Anchor |
Statement |
t1 |
events |
sort timestamp |
t2 |
segment value; change; as gid |
|
t3 |
summarize timestamp first as effective_from, id first as id; group gid, value |
|
t4 |
compute nvl(effective_from[1],datetime("9999-12-31 00:00:00")) as effective_to |
|
derive delete gid |
Step 1: Sort records by timestamp to ensure that they are processed in chronological order
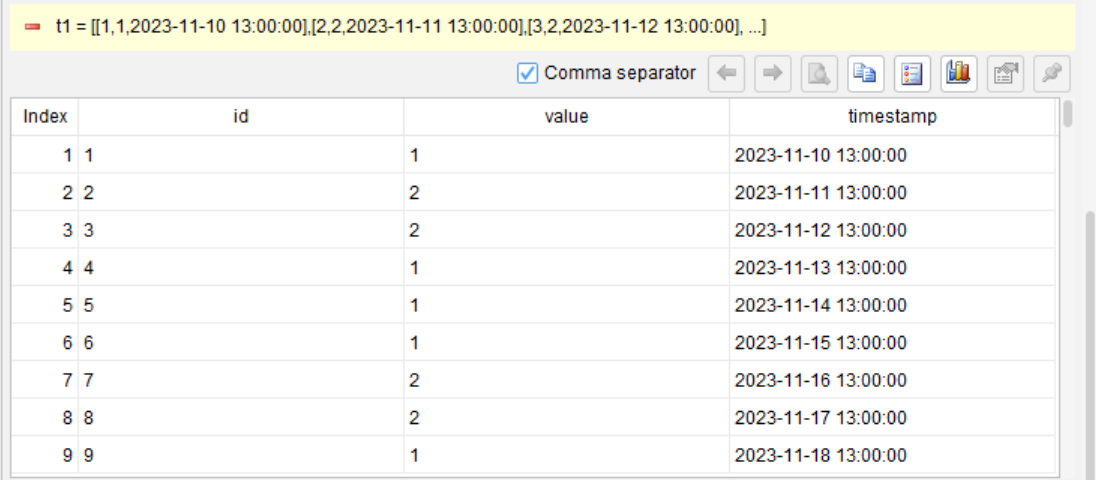
Step 2: Generate group IDs by comparing and grouping adjacent records
This step is crucial. The “segment” operation divides the records into multiple groups by traversing the data: whenever the value field changes, a new group is created and the group ID (gid) is automatically generated.
After running this step, the intermediate table will include a new column called gid.
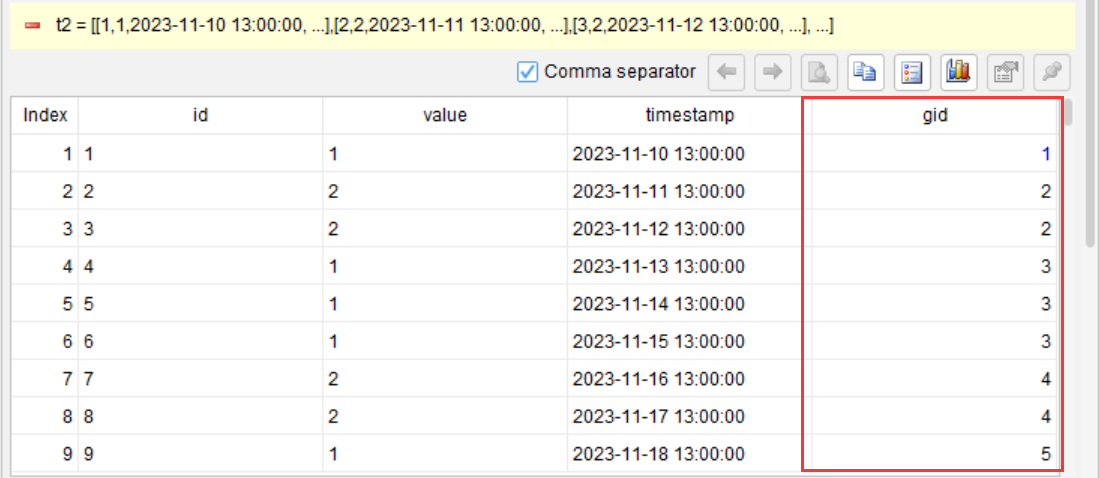
Notice how the gid changes: when the value changes from 1 to 2, a new group begins; when it stays at 2, the records belong to the same group; when it changes from 2 back to 1, another new group begins.
Step 3: Group the data and select the first record from each group
For each gid (retain the value field), take the earliest timestamp in the group as effective_from, and use the first id in the group as the representative id (since ids are increasing, this corresponds to the smallest id within the group).
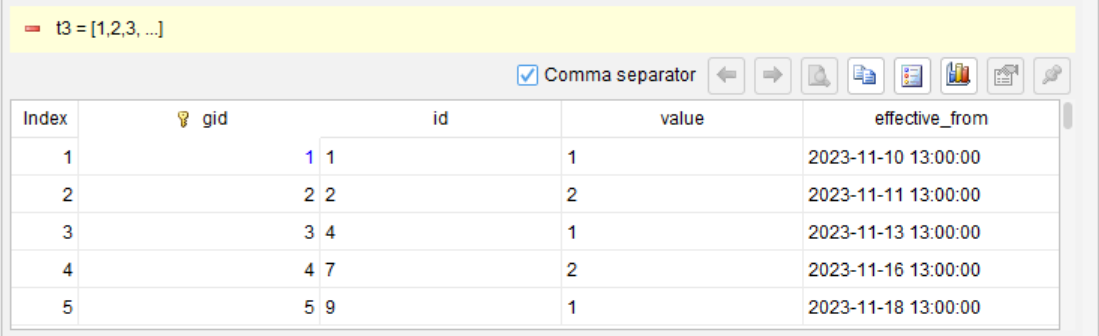
Step 4: Compute the end timestamp (the start timestamp of the next group)
Here, effective_from[1] represents “the effective_from value in the next row” (similar to the SQL LEAD function). nvl handles the case where there is no next row for the last group, by filling in a predefined maximum date.
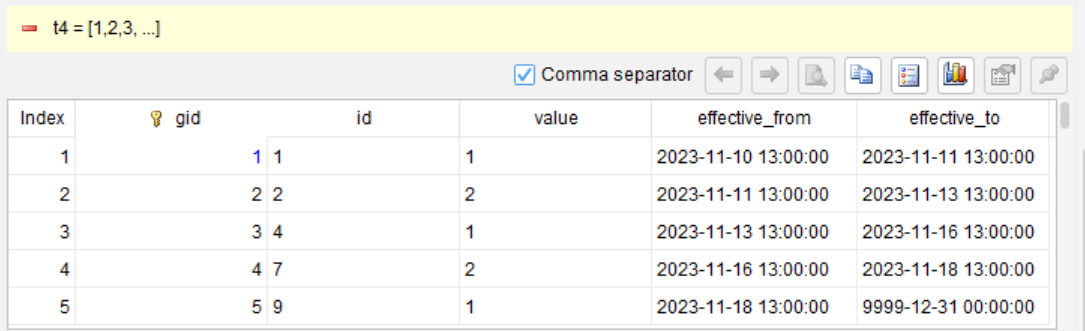
Step 5: Remove the helper column gid
This step simply cleans up the output by removing the temporary gid column, and get the final result.
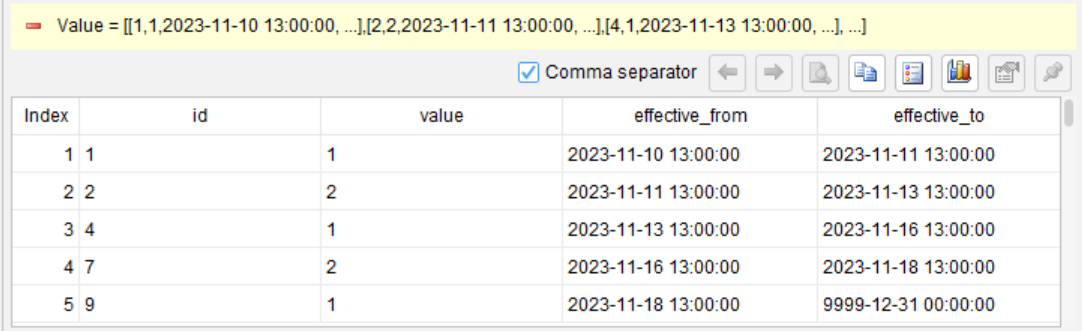
Once each step and its result have been verified, compile the workflow into the target SQL dialect (Oracle in this example).
WITH Value AS (
SELECT
id,
value,
timestamp
FROM
events
),
Value2 AS (
SELECT
gid,
id AS id,
value AS value,
timestamp AS effective_from
FROM
(
SELECT
id,
value,
timestamp,
SUM(
CASE
WHEN value <> col__5 THEN 1
ELSE 0
END
) OVER (
ORDER BY
CASE
WHEN timestamp IS NULL THEN 1
ELSE 0
END,
timestamp ASC
) + 1 AS gid
FROM
(
SELECT
Value.*,
LAG(value) OVER (
ORDER BY
CASE
WHEN timestamp IS NULL THEN 1
ELSE 0
END,
timestamp ASC
) AS col__5
FROM
Value
) sub__6
) Value1
GROUP BY
gid
)
SELECT
gid,
id,
value,
effective_from,
LEAD(
effective_from,
1,
TO_DATE('9999-12-31 00:00:00', 'YYYY-MM-DD HH24:MI:SS') OVER (
ORDER BY
gid
)
) AS effective_to
FROM
Value2
ORDER BY
gid
The compiler ultimately generates a complex SQL query containing nested window functions and subqueries. Within the SQLazy frame, however, you do not need to review that SQL. You only need to verify that each step of the workflow is logically correct. Once the logic is validated, the compiler ensures that the final output is correct by construction.
This is the key difference between SQLazy and other AI SQL generators:
Other AI SQL generators |
SQLazy |
|
Input |
Queries expressed by the natural language |
step-by-step logic |
Output |
The final SQL |
First write runnable steps of logic, and then compile them into SQL |
How to debug |
Manual breakdown, and repeated trial and error |
Run step by step, where you can inspect intermediate results immediately |
The role of AI |
Generate the final SQL in a black-box manner |
Help organize the idea but do not directly generate the final code |
Auditability |
Low – no choice but to trust AI |
High – verify result at each step |
Maintainability |
Low – difficult to read SQL and untraceable prompt |
High – steps are dynamic documents |
Cross-database portability |
May confuse one database type with another |
The compiler automatically generates reliable multiple SQL dialects |
AI hallucination |
Frequently occurs |
The compiler generates the final SQL without any hallucinations |
Generating correct complex SQL is not the end of the story – SQLazy goes further and solves the following challenges:
1. Hard to review
A 50-line SQL block with four levels of nested subqueries and three window functions is difficult even for seasoned developers to quickly determine whether the logic is correct. SQLazy’s step-by-step approach makes review extremely simple: you only need to check the order and conditions across 5-7 steps, where the input and output of each step are clearly visible. Even business stakeholders and product managers can participate in validating the logic.
2. Hard to debug
Traditional SQL debugging is a black-box experience: you can see the final result, but you have little visibility into the intermediate steps. Where did the logic go wrong? It’s hard to tell. The only choice is to add debug fields, comment out some subqueries, and run the query again and again. SQLazy enables step-by-step execution, allowing you to inspect the intermediate table produced at each step. Suppose the grouping condition at step 3 gets wrong, you can fix it immediately and the subsequent steps are automatically recomputed. What used to take hours of debugging can now be resolved in minutes.
3. Hard to maintain
You open a complex SQL file written three months ago. Now the requirements are changed. You stare at the window functions, wondering: “What was this LAG supposed to do?” Worse still, the original requirements may have already been lost. In SQLazy, the steps themselves serve as living documentation. Even a new team member can understand the logic within minutes of opening the workflow. To update requirements, you simply modify the corresponding step and let the compiler regenerate the SQL.
4. Hard to port across databases
Suppose you need to migrate code from Oracle to PostgreSQL: DECODE must be replaced with CASE, ROWNUM with LIMIT, and TO_DATE requires different formatting. SQLazy’s compiler has built-in support for three SQL dialects – MySQL, PostgreSQL, and Oracle, with Snowflake and BigQuery coming soon. Write the steps once, generate SQL for multiple dialects, and reduce migration cost to zero.
Audit and compliance: the often overlooked value
In highly regulated sectors such as finance, healthcare, and government, auditability of data queries is a strict requirement. Compliance teams need to know how are the numbers in this report computed, who wrote the logic, and whether it has been validated?
Ordinary AI-generated SQL cannot answer these questions. You can only present a snippet of code and say, “This was generated by ChatGPT.” Compliance auditors will not accept that.
SQLazy’s step-by-step workflow naturally satisfies auditing requirements:
Each step is clearly described.
You can take a screenshot of the result at each step for documentation.
The deterministic nature of the compiler guarantees that the same steps always produce the same SQL.
Version control is easy because the workflow file can be committed to Git like code.
This enables a complete audit trail that is traceable, interpretable, and reproducible when an auditor asks, “Why does this figure show 20% rather than 30%?”
SQLazy’s positioning: what problems does it solve?
SQLazy is designed for a specific category of SQL workloads: complex, medium-to-heavy analytical scenarios that are difficult to reason about. For example:
Continuous trend and rising/falling period analysis, such as “calculating the longest consecutive rising streak in a stock”.
Event sequence & dialogue segmentation for user behavior path analysis.
Dynamic conditional grouping according to different aggregation method for different customer groups.
Time window analysis, which involves rolling calculation and missing value imputation.
Financial transaction metrics calculation.
The examples directory in SQLazy’s GitHub repository contains many real-world cases for these scenarios.
But in certain scenarios, SQLazy is not necessary:
Simple queries involving only 3-5 code lines.
An expert at writing window functions manually, with no need for third-party review.
A one-person team with no requirement for documentation and review.
At the moment when the AI wave sweeps through everything, particularly the coding field, SQLazy emerges to offer a different technological framework.
SQLazy recognizes AI’s efficiency superiority while rejecting unquestioning acceptance. It upholds the philosophy that humans should be responsible for the final output and that AI should only serve as the consultant rather than the decision-maker. It uses the compiler, the validation tool, to make up for the inconsistency of AI-generated output. Simply put, AI plans, the compiler guarantees correct output.
Indeed, there is still room to improve SQLazy: although both the desktop and web versions are free to use, the tool itself is not open-source; and some advanced features are still under development. However, in the long run, the methodology behind SQLazy may prove more resilient than simply using AI to replace SQL writing. This is because it not only improves development efficiency, but also preserves human control over critical decision-making in the AI era, while helping to establish an auditable, maintainable, and portable data asset system.
Rather than blindly accepting a SQL black box you don’t even fully understand, it is better to break down the logic into explicit steps and let the compiler handle the final execution. SQLazy makes this workflow possible.
Try SQLazy online: sqlazy.com (Free to use, signup not required)
Project repository: github.com/SPLWare/SQLazy
Case collection: github.com/SPLWare/sqlazy/tree/master/examples
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version