

A Field Guide to Querying and Report Computations with SPL - 5 Align and group data by members of an external set
This type of tasks involves grouping data by members of an external set, rather than by field values of the set of records itself or a set of computed column values. SQL does not support data grouping directly by an external set. It needs to associate with an external table or perform union of multiple subqueries. The approach is rigid and makes code difficult to write. The SQL code becomes even harder to write when there isn’t a one-to-one correspondence between records of the set and members of the external set and extra members need to be handled.
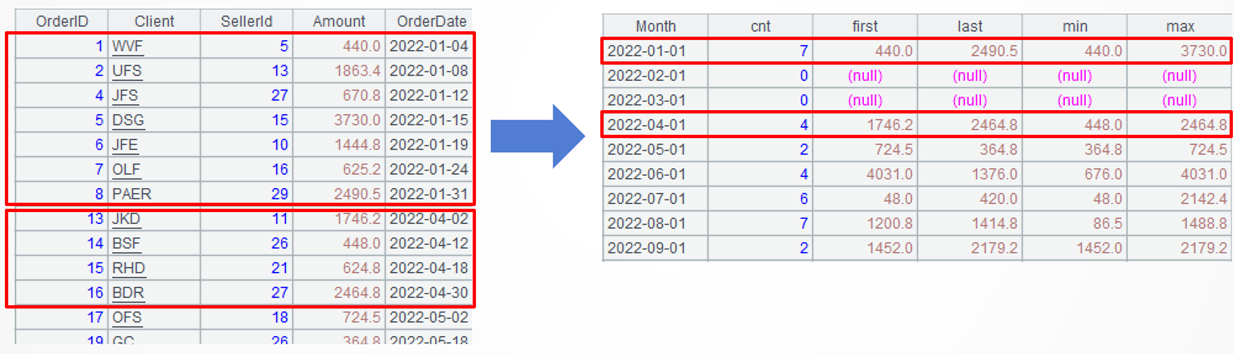
Example 1: Perform aggregations on discontinuous orders according to continuous months
Source data: An orders table where not every month has records (5\OrdersUncontinuous.txt)
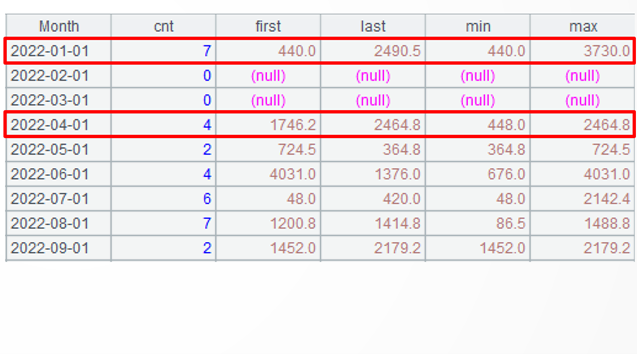
Target: Group records by month in the chronological order, and find order volume per month, amounts of the first order and the last order and those of the smallest order and the largest order. For months that do not have any orders, those values also need to be computed.
![]()
SPL code:
A |
|
1 |
$select * from 5\OrdersUncontinuous.txt order by OrderDate |
2 |
=A1.run(OrderDate=pdate@m(OrderDate)) |
3 |
=list=periods@m(A1.min(OrderDate),A1.max(OrderDate)) |
4 |
=A1.align@a(list,OrderDate) |
5 |
=A4.new(list(#):Month,~.count():cnt, ~.m(1).Amount:first, ~.m(-1).Amount:last, ~.min(Amount):min, ~.max(Amount):max) |
A1: Load data, during which records are sorted by order date.
A2: Modify OrderDate value as the first date of the current month.
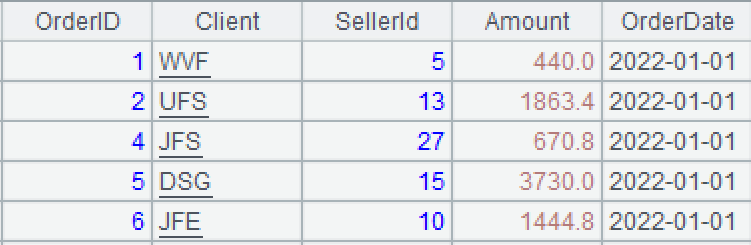
A3: Generate a sequence of continuous months named list, where each member corresponds to a month. The periods() function generates continuous dates using the specified starting and ending dates; the default interval unit is day. @m option implies the interval unit is month; and the default interval is 1.
A4: Align orders records to list – each group contains records of one month. Certain months may have empty data. The align@a() function aligns orders records to the list and group them by it.
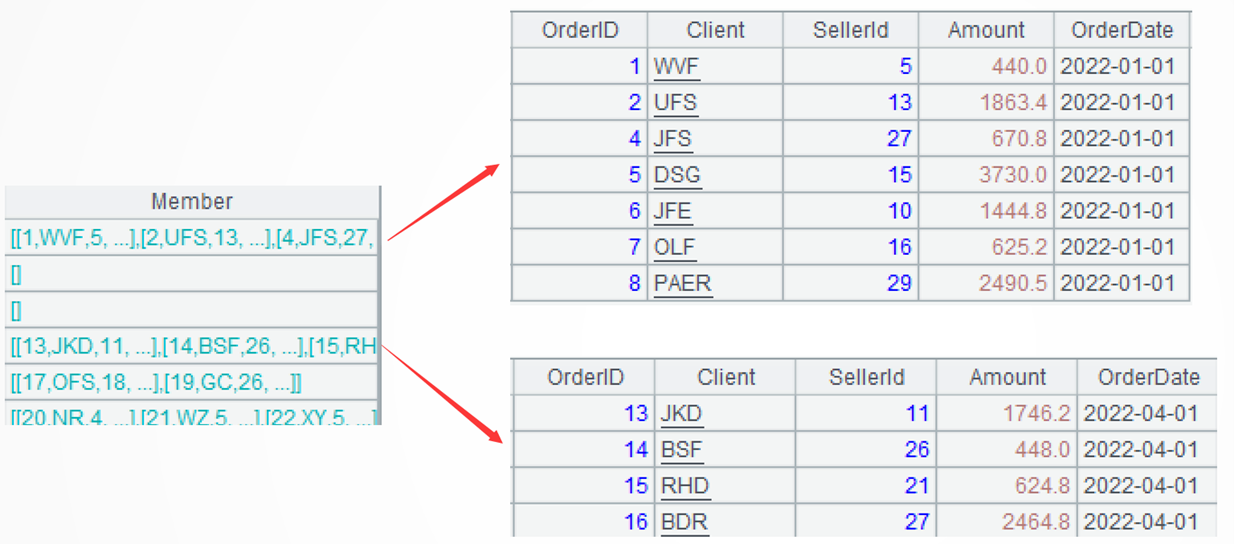
Learning point: Alignment grouping
SPL align() function aligns and groups a set of records according to an external set. If there are extra members in the set of records, they do not have corresponding groups; if the external set has extra members, their corresponding groups are empty. The function returns the first member of each group by default; @a option enables returning all members.

Parameter A: The external set represented by a field of an external set of records or its expression and written in the form of “set name:field name/expression”.
Parameter y: A field/expression of the to-be-grouped set of records.
A5: Generate a two-dimensional table – A4’s each group of records corresponds to a new record. Month value is the list member with the corresponding sequence number represented by #. The other fields are order volume per month, amount of the first order, amount of the last order, amount of the smallest order, and amount of the largest order. The m() function gets a member according to the sequence number. A negative sequence number denotes a member counted backwards; when the sequence number isn’t specified, the function gets no members.
Example 2: Aggregation on employees of each department in key states and other states
Source data: Employee table
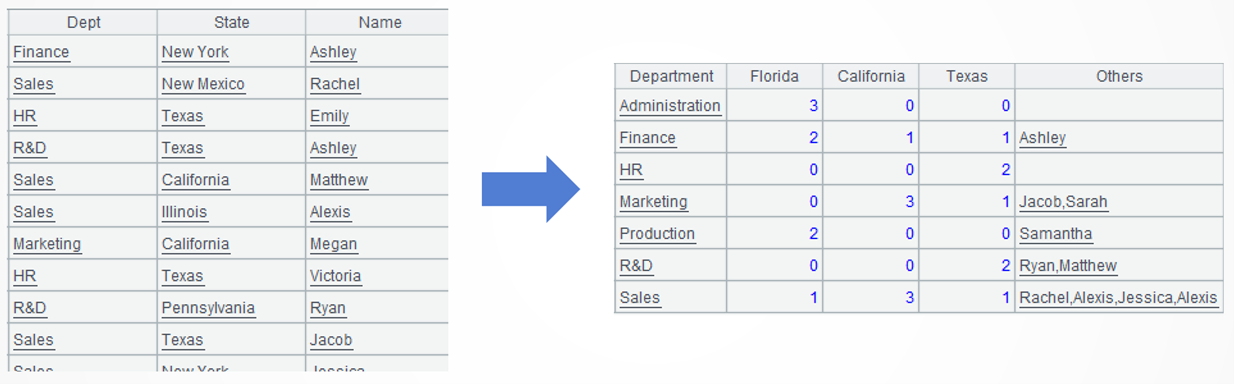
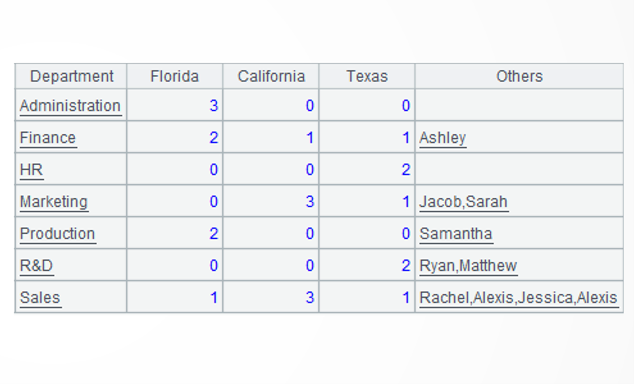
Target: Display data of employees of each department in every state with a crosstab. The row headers are departments, and the column headers are three key states and other states. Under the three key states count the number of employees, and in the last column concatenate names of employees in all the other states.
SPL code:
A |
|
1 |
$select Dept,State,Name from Employee.txt |
2 |
=A1.group(Dept) |
3 |
=A2.(~.align@n(["Florida","California","Texas"],State)) |
4 |
=A3.new(~.ifn(Dept):Department,~(1).count():Florida,~(2).count():California,~(3).count():Texas, ~(4).(Name).concat@c():Others) |
A1: Load data.
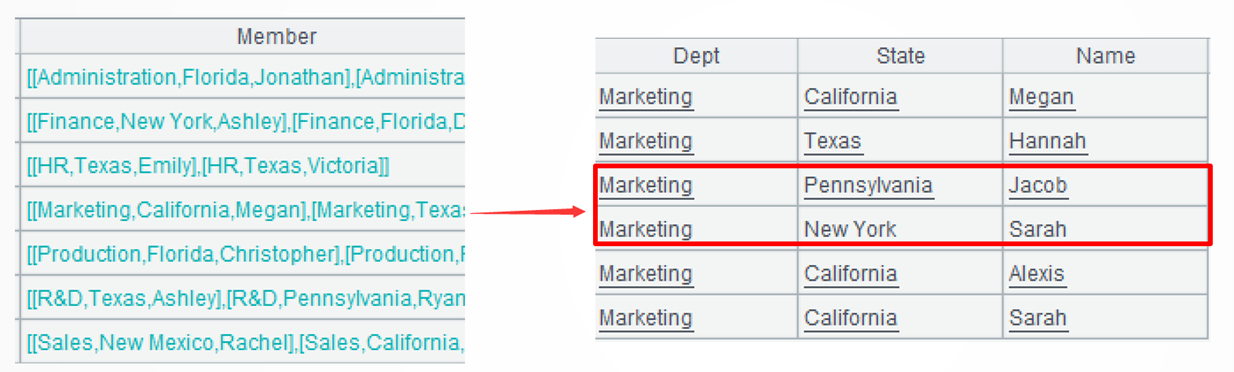
A2: Group records by department. Each group consists of a set. Below is the 4th group:
A3: Process each group of data: align the current group with the key states and put records without matches in the last group. Below shows details in the 4th group:
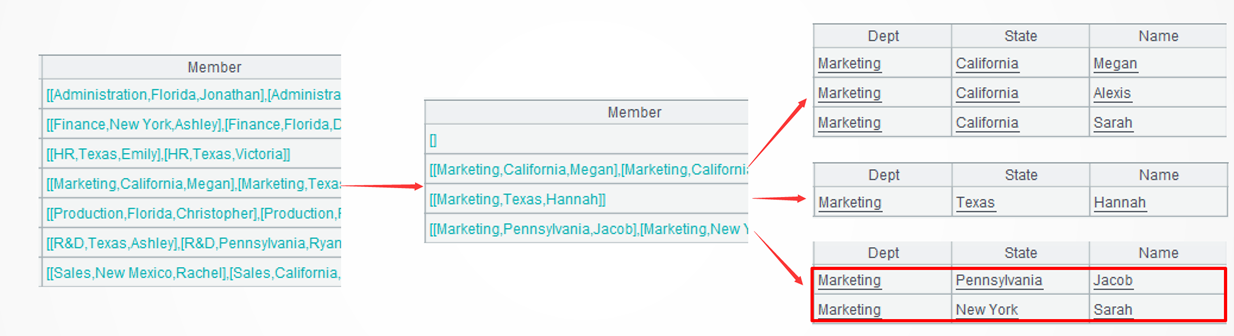
The align@n function puts records without matches in the last group during the alignment grouping.
Learning point: Alignment grouping’s @n option
When performing the alignment grouping, the align() function can work with @n option to put records in the set that do not match the external set, the extra records in other words, to the last group.
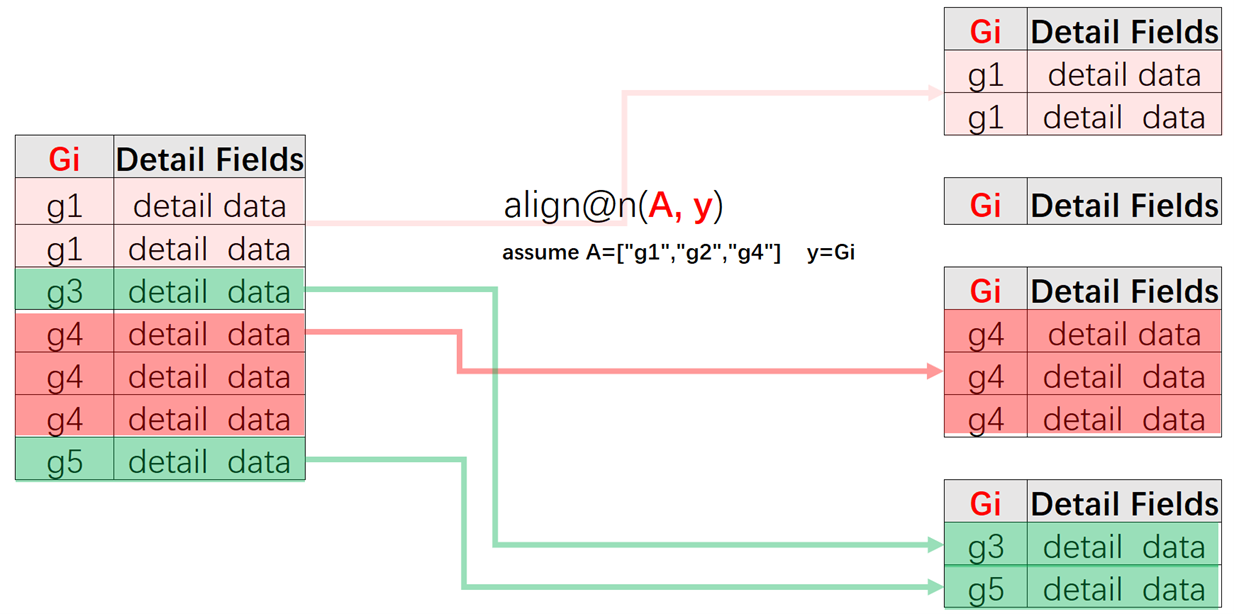
A4: Generate a new two-dimensional table, where each record corresponds to a group. The “Department” column value is the first non-null member of the set of departments in the current group. “Florida” column value is the number of members of the first subgroup in the current group. Obtain values of the other two key states in the same way. “Others” column value is employee names in the current group’s 4th subgroup, and use comma to concatenate these names. The ifn()function returns the first non-null member of a set. The concat() function concatenates members of a set using the specified separator; @c option enables using comma as the separator.
Extended reading
How to generate a list of fixed duration windows and perform statistics with esProc
https://c.raqsoft.com.cn/article/1549182237531
https://c.raqsoft.com.cn/article/1547520280708
https://c.raqsoft.com.cn/article/1571412914244
https://c.raqsoft.com.cn/article/1572224318205
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL

