

A Field Guide to Querying and Report Computations with SPL - 1 Computing and processing grouped subsets
1 Computing and processing grouped subsets
When a set is grouped, each group of data is a subset of the original set, which is referred to as grouped subsets. This type of challenge involves not immediately aggregating data after grouping but instead retaining the grouped subsets for further computations. In SQL, aggregation must be performed immediately after grouping, and it is not possible to directly retain grouped subsets for later computations. Typically, the computing target can only be achieved indirectly, resulting in complex code.
Example 1: Get records where there are more than 5 employees in the department and sort records in each department by salary

SPL code:
A |
|
1 |
$select * from Employee.txt |
2 |
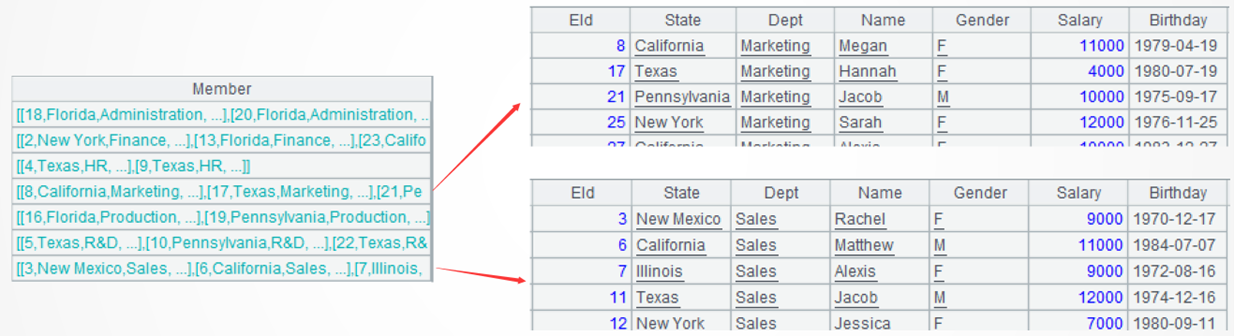
=A1.group(Dept) |
3 |
=A2.select(~.len()>5).(~.sort(Salary)) |
4 |
=A3.conj() |
A1: Load data.
A2: Use group() function to group A1 by department, without aggregation.
l Learning point: Grouping function – group()
In addition to groups(), the common grouping & aggregation function, SPL also has a more fundamentalgroup()function, which retains the set of records in each group for subsequent computations. SQL, however, requires immediate aggregation after a grouping operation. The set of records in each group is a subset of the set of records (or references to the records) of the original table sequence, also referred to as a grouped subset.
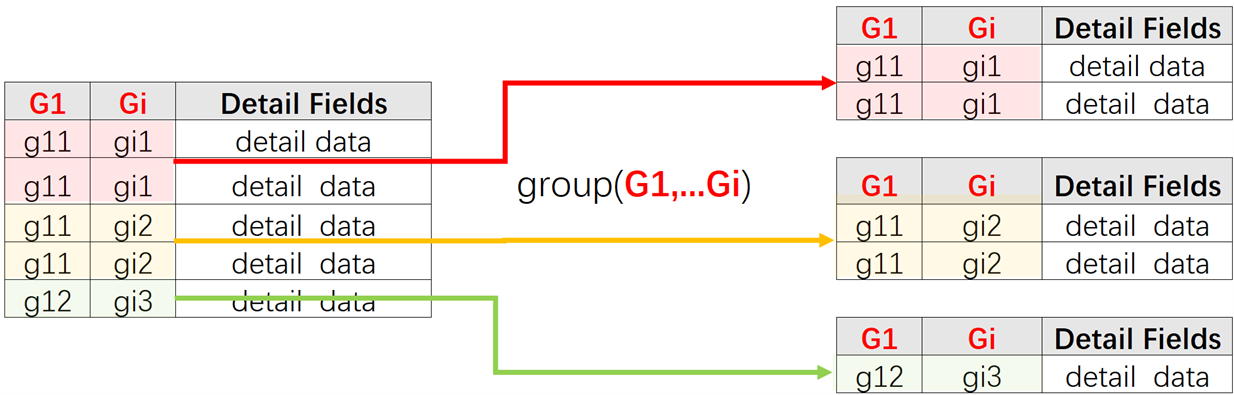
Parameters G1…Gi: Grouping expressions, which are separated by commas when there are multiple.
A3: Process each group of data – get departments having more than 5 employees and sort the employee records in each group by salary. ~ is a SPL reserved word, representing the current group. The select()function performs filtering operation, sort() function sorts data, and len() function counts members of a set.
A4: Use conj() function to concatenate employee records of different departments.
A2-A4 is the stepwise code, which is debug-friendly. They can be combined into one statement:
A1.group(Dept). select(~.len()>5).conj(~.sort(Salary))
Example 2: Retain only the first client’s name in each group after sorting Orders table by client and amount
Data source: After sorting Orders table by client and sales amount, it can be observed that each client forms a group of data, in which order records are arranged in ascending order by amount.
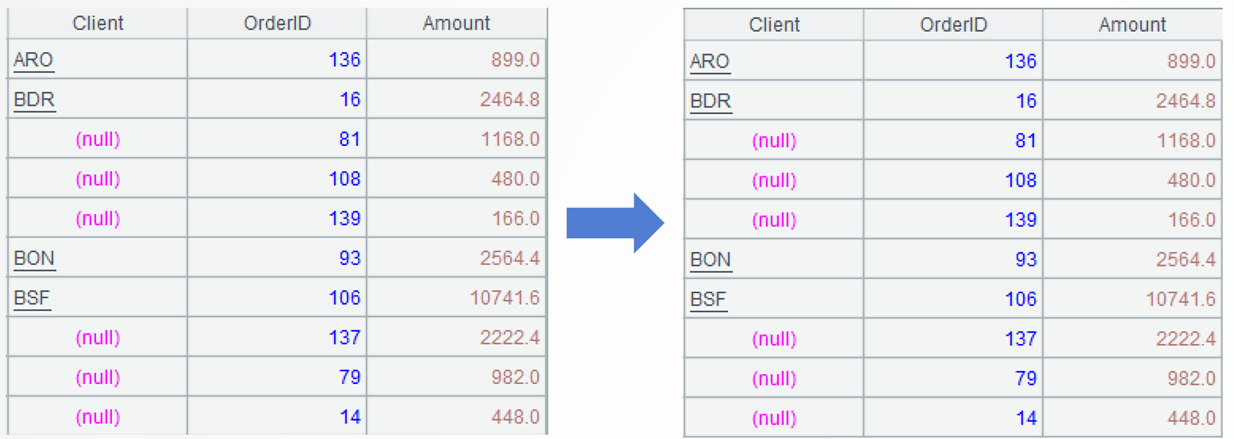
Target: Retain the first client in each group and modify Client value in each of the other records in the group into null.
SPL code:
A |
|
1 |
$select Client, OrderID, Amount from Orders.txt order by Client,Amount DESC |
2 |
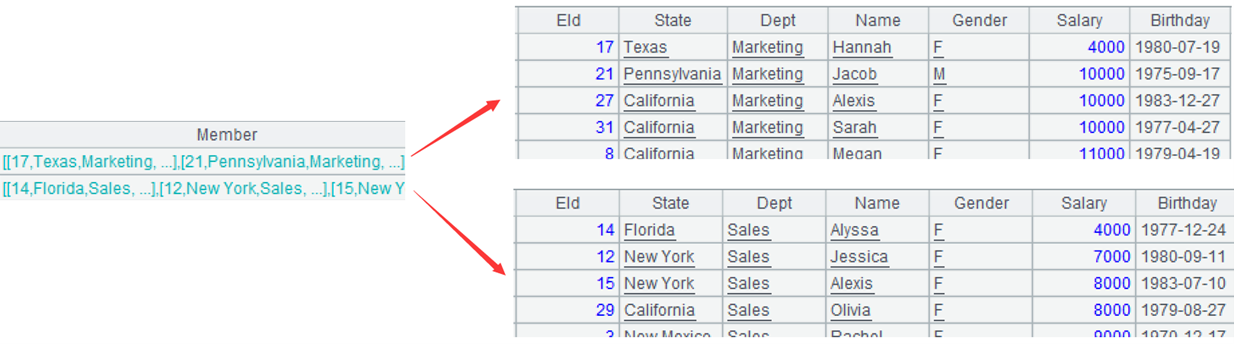
=A1.group(Client) |
3 |
=A2.run(~.(if(#>1,Client=null))) |
4 |
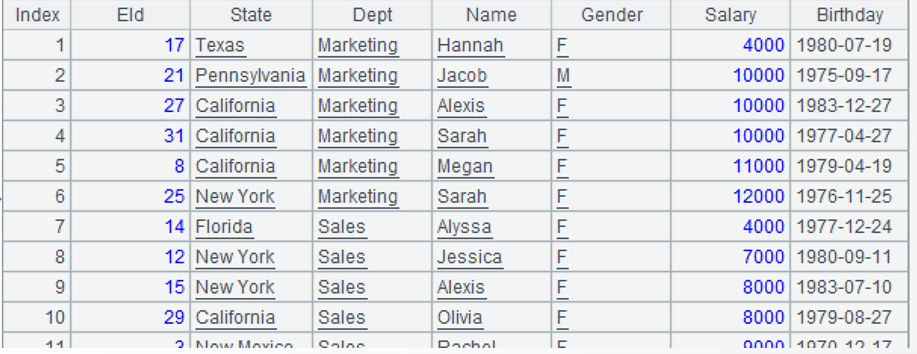
=A3.conj() |
A1: Load data.
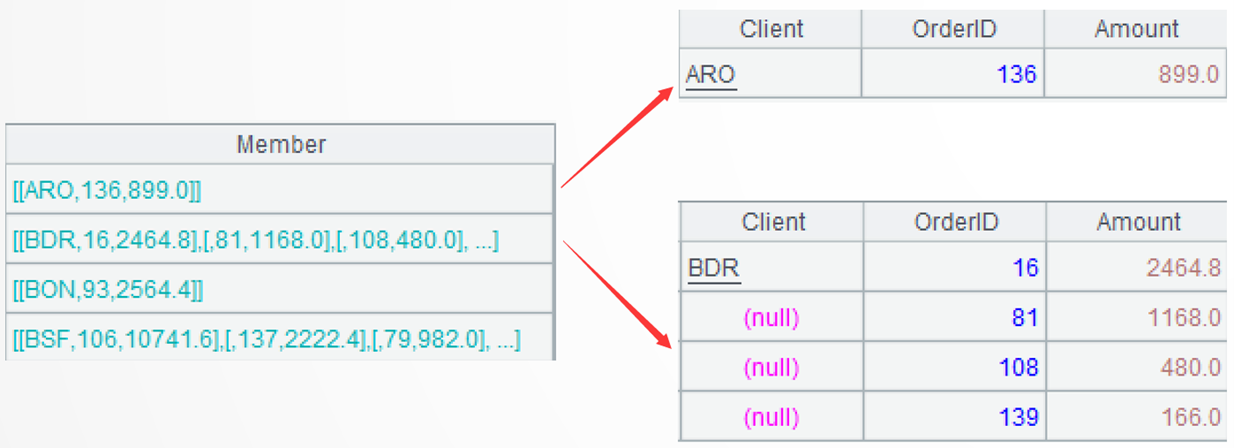
A2: Group A1 by client; each group consists of a set. Below shows data in the first two groups:

A3: Use run() function to modify data of each group. When the sequence number of a member is greater than 1, modify the current Client value into null. ~ represents the current group, and # represents sequence number of a member of the current group.
A4: Concatenate members from all groups.
Example 3: Implement DISTINCT operation by performing a secondary grouping on same-ID Orders records according to a specified condition
Data source: An orders table having duplicate order IDs (such as 1\OrdersDup.txt)
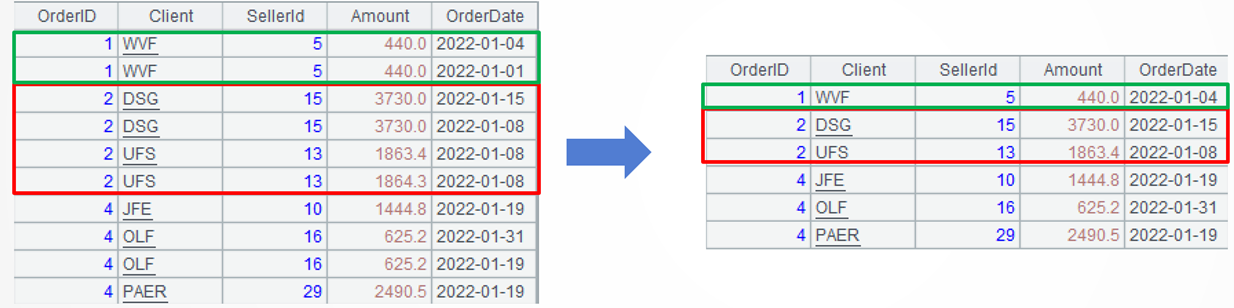
Target: Remove duplicate order records. First, group records by order IDs; then, based on if there are duplicate order dates within each group, decide whether to perform a secondary grouping: if there are no duplicates, retain the order record with the most recent date; if there are duplicates, further group the records by customer and similarly retain the order record with the most recent date in each subgroup. After the grouping operations are done, there is no need to renumber the order IDs.
SPL code:
A |
|
1 |
$select * from 1\OrdersDup.txt order by OrderDate desc |
2 |
=A1.group(OrderID) |
3 |
=A2.conj(if(~.icount(OrderDate)==~.count(), [~], ~.group(Client))) |
4 |
=A3.(~(1)) |
A1: Load data, during which record with more recent dates are placed first.
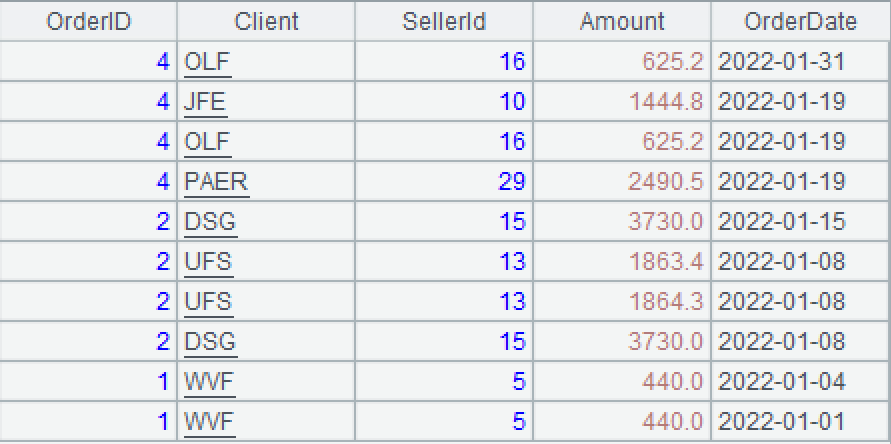
A2: Use group() function to group records by order IDs without aggregation. Each group is a set.
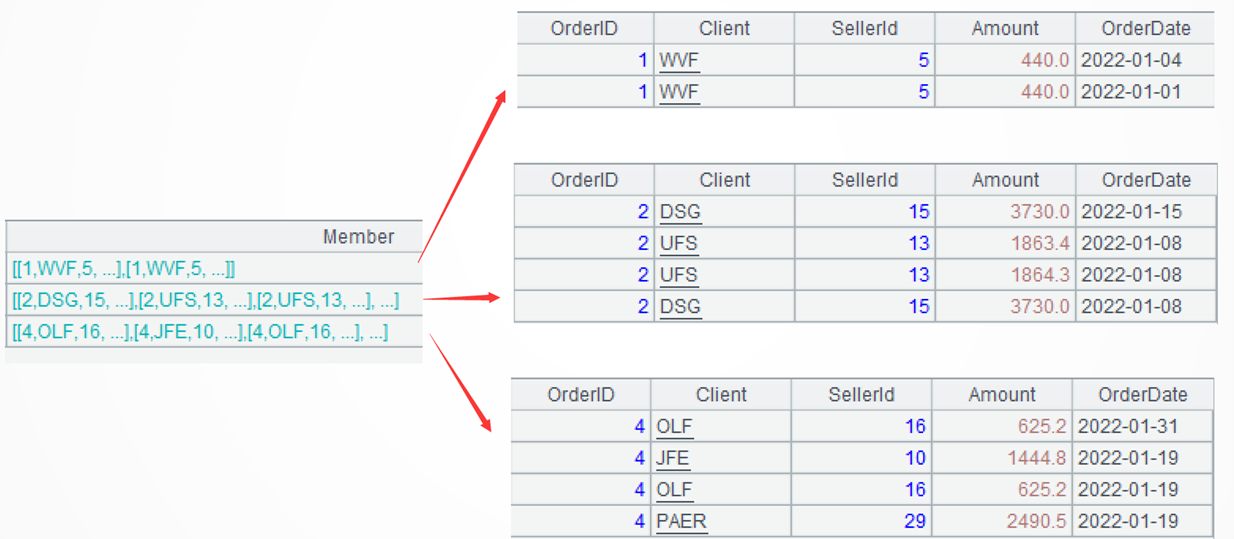
A3=…(if(~.icount(OrderDate)==~.count(), [~], ~.group(Client)))processes each group of data. If there are no duplicate dates in the current group, return the current group (for example, Group 1); otherwise, further divide records in the group by customer, also without aggregation, and return each subgroup, a set of sets (for example, Groups 2 and 3). Here,~represents the current group. Theicount()function counts the number of distinct members, while thecount()function counts all members. The square brackets[]represents a set. Since~itself is a set,[~]represents a set of set. This approach ensures consistent data structure throughout, facilitating processing with the same method.
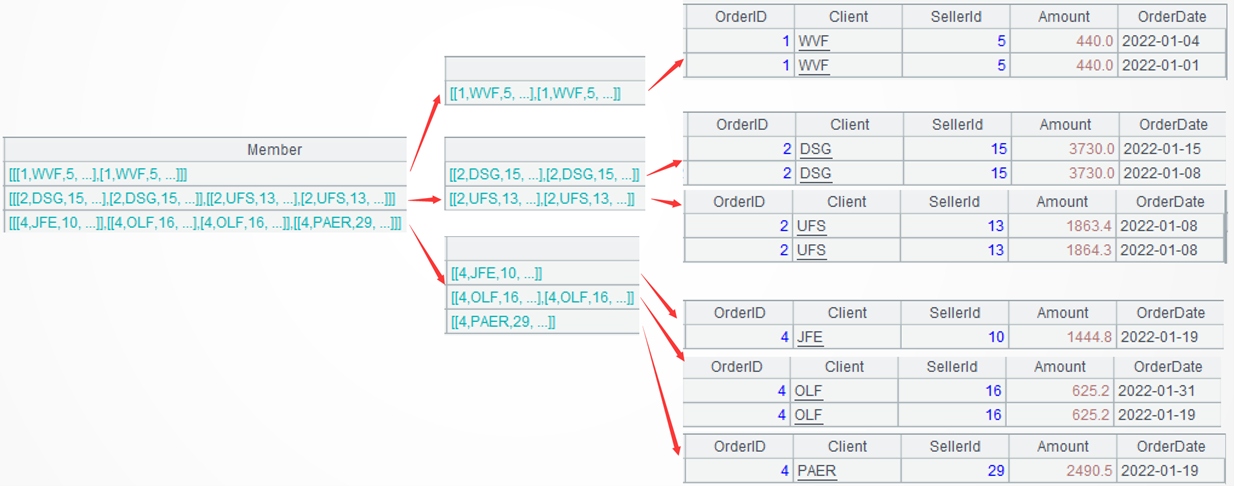
conj(…) concatenates members from all groups after the above processing, converting the two-level set (a set of sets) in each group to a single-level set.
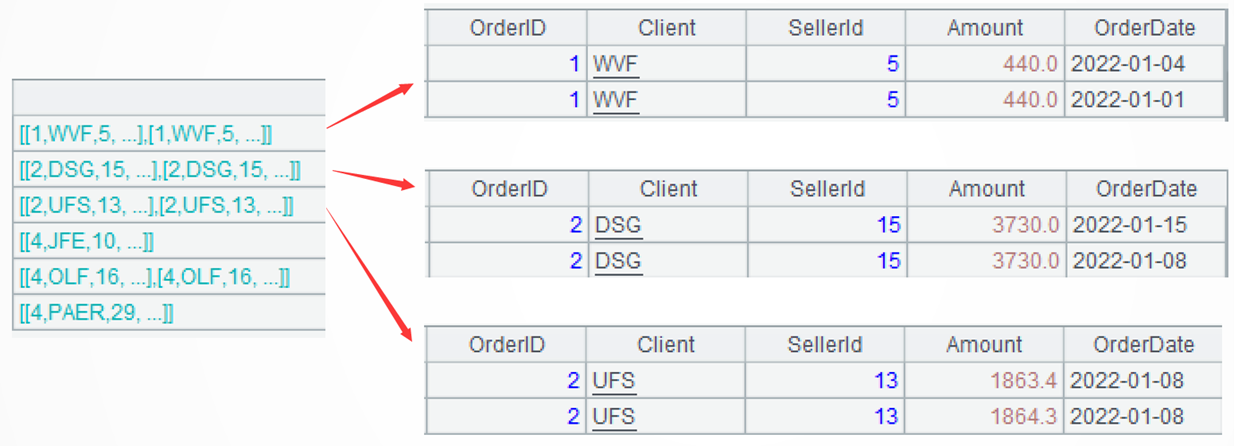
A4: Process the grouped data in A3 uniformly: retrieve the first record of the current group. ~.(1) represents the first member of the current group, which can be abbreviated as ~1.
Extended reading
From SQL to SPL: Complement a certain average value to ensure that the total sum remains unchanged
How to set duplicate content in a dataset to null with esProc
How to perform secondary grouping based on conditions within the grouped subsets with esProc
From SQL to SPL: Count distinct within intervals in order
esProc SPL’s Grouping Operations: The Most Powerful in History, Bar None
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL

