

How to perform secondary grouping based on conditions within the grouped subsets with esProc
The first four fields of a certain database table can all be grouping fields.
ID |
SPLIT |
CUST |
DATE |
AMOUNT |
ID_1 |
SPLIT_YES |
A |
2024-05-01 00:00:00 |
100 |
ID_1 |
SPLIT_NO |
A |
2024-04-01 00:00:00 |
200 |
ID_1 |
SPLIT_YES |
B |
2024-03-01 00:00:00 |
50 |
ID_2 |
SPLIT_YES |
A |
2024-05-01 00:00:00 |
50 |
ID_2 |
SPLIT_NO |
A |
2024-04-01 00:00:00 |
300 |
ID_2 |
SPLIT_NO |
B |
2024-03-01 00:00:00 |
300 |
ID_3 |
SPLIT_YES |
B |
2024-04-01 00:00:00 |
90 |
ID_3 |
SPLIT_NO |
B |
2024-04-01 00:00:00 |
30 |
ID_3 |
SPLIT_NO |
A |
2024-04-01 00:00:00 |
10 |
ID_3 |
SPLIT_NO |
A |
2024-03-01 00:00:00 |
10 |
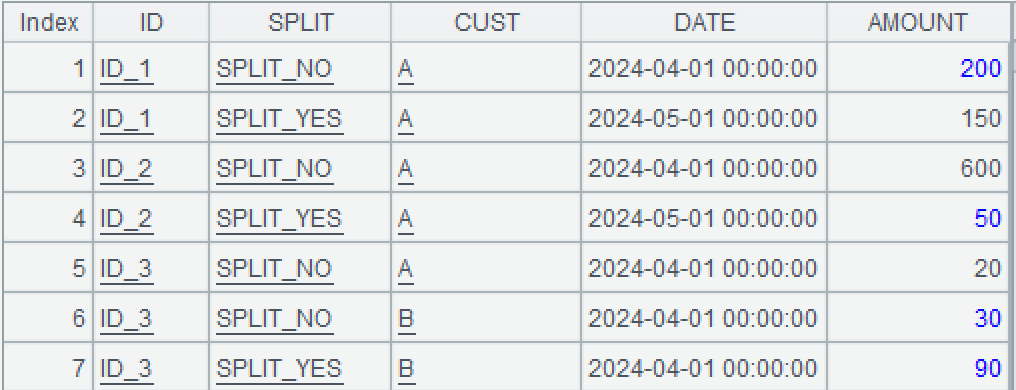
Now group by the first two fields ID and SPLIT, and then decide whether to continue grouping again based on the conditions: if there are no duplicate DATEs within the group, keep the record with the latest date in this group and replace AMOUNT with the sum of AMOUNTs in this group; If there are duplicate dates within the group, group the records of this group again by CUST, while retaining the record with the latest date in the current group, and also replace the AMOUNT with the sum of the AMOUNTs of the current group.
SQL grouping must aggregate immediately after grouping, and cannot retain the grouped subsets, resulting in complex code for indirect implementation. SPL can retain subsets for further calculation, and subsets can also continue to be grouped:
https://try.esproc.com/splx?44C
A |
|
1 |
$select * from test_table_mm.txt order by DATE desc |
2 |
=A1.group(ID,SPLIT) |
3 |
=A2.conj(if(~.icount(DATE)==~.count(), [~], ~.group(CUST))) |
4 |
=A3.(~(1).run(AMOUNT=A3.~.sum(AMOUNT))) |
A1: Load data, with records with recent dates listed first.
A2: Use the group function to group by the first two fields, but do not aggregate them. Each group is a set. The figure shows the first and fifth groups.
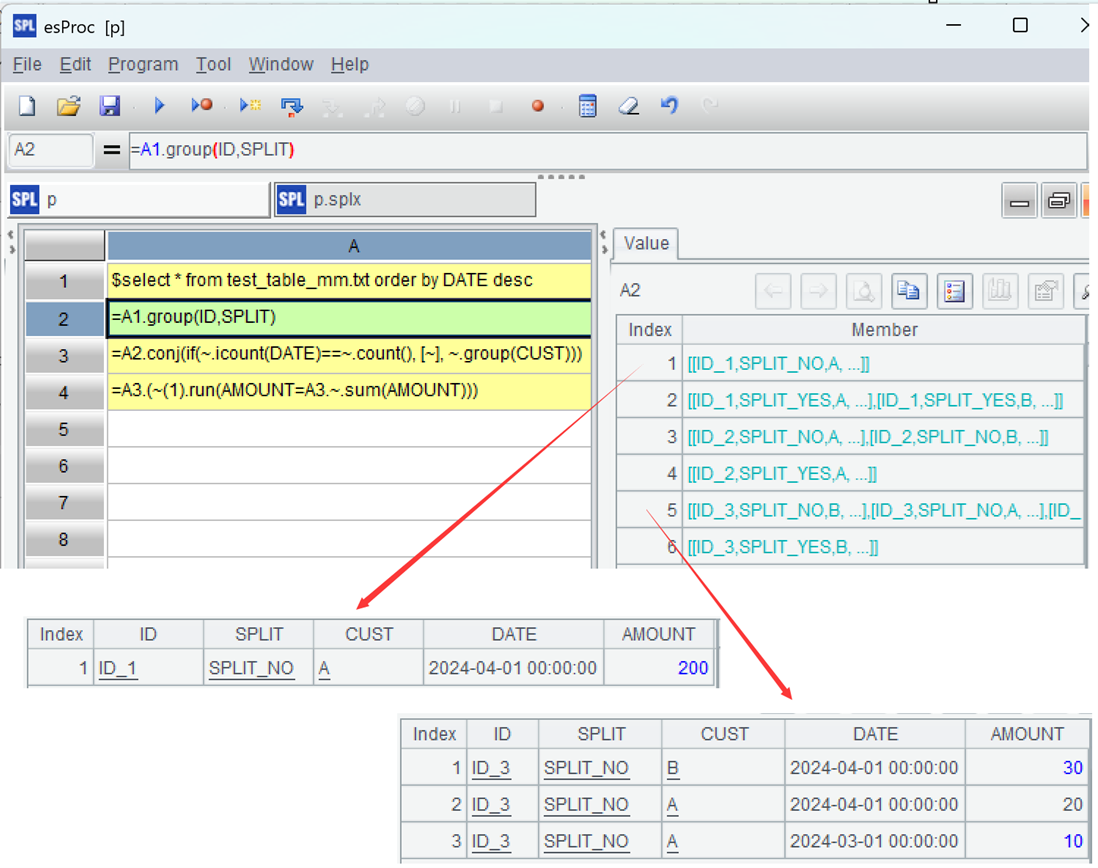
A3:(if(~.icount(DATE)==~.count(), [~], ~.group(CUST))), process each group of data, and if the dates in this group are not duplicated, return the current group, such as the first group; Otherwise, continue grouping the current group by CUST and return each group, which is the sets of a set, such as the fifth group. ~ indicates the current group. The function icount is used to count the number of unique members. The count function is used to count the number of members. [] is a set symbol, because ~ itself is a set, [~] is a set of sets. This processing can make the data structure consistent and facilitate unified processing. The figure shows the first and fifth groups.
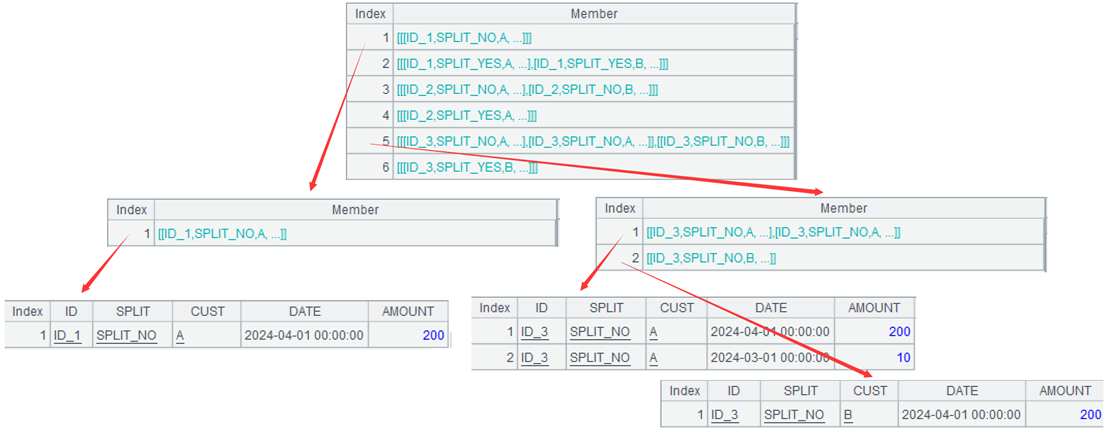
conj(…), merge the processed groups of data, so that each group of data rises from a 2-layer set (set of sets) to a single-layer set. Among them, the original group 5, due to continued grouping, had two sets of sets, which were merged and raised to two sets:

A4: Unified processing of data for each group in A3: Take the first record of the current group and replace AMOUNT with the sum of AMOUNTs for the current group. (1) represents the first member of the set.
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL

