

How to Speed Up COUNT DISTINCT with esProc
The COUNT DISTINCT in SQL has always been relatively slow.
De-duplication is essentially a grouping operation that requires retaining all the traversed grouping field values for subsequent comparisons. When the result set is too large, the data must also be written to hard drive for buffering, which leads to poor performance.
If the data is first sorted by the de-duplication field, calculating ordered de-duplication will be much simpler, as it only requires saving the field that differs from the previous record during traversal and incrementing the count by 1. This eliminates the need to retain the result set, let alone buffer data on external storage.
However, because databases cannot guarantee the order of storage, implementing such an ordered de-duplication algorithm is difficult. esProc SPL can export data and store it in order, enabling this high-performance, ordered de-duplication count.
Below, we will compare the performance of esProc SPL and MySQL database in calculating de-duplication count through a few practical examples.
Test environment: Ordinary laptop computer, 2-core CPU, 8GB RAM, SSD. The operating system is Win11, and the MySQL version is 8.0.
The events table in the database contains 10 million records, including the fields: event_id, user_id, event_time, and event_name.
First, download esProc at https://www.esproc.com/download-esproc/. The standard version is sufficient.
After installing esProc, test whether the IDE can access the database normally. First, place the JDBC driver of the MySQL database in the directory ‘[Installation Directory]\common\jdbc,’ which is one of esProc’s classpath directories.

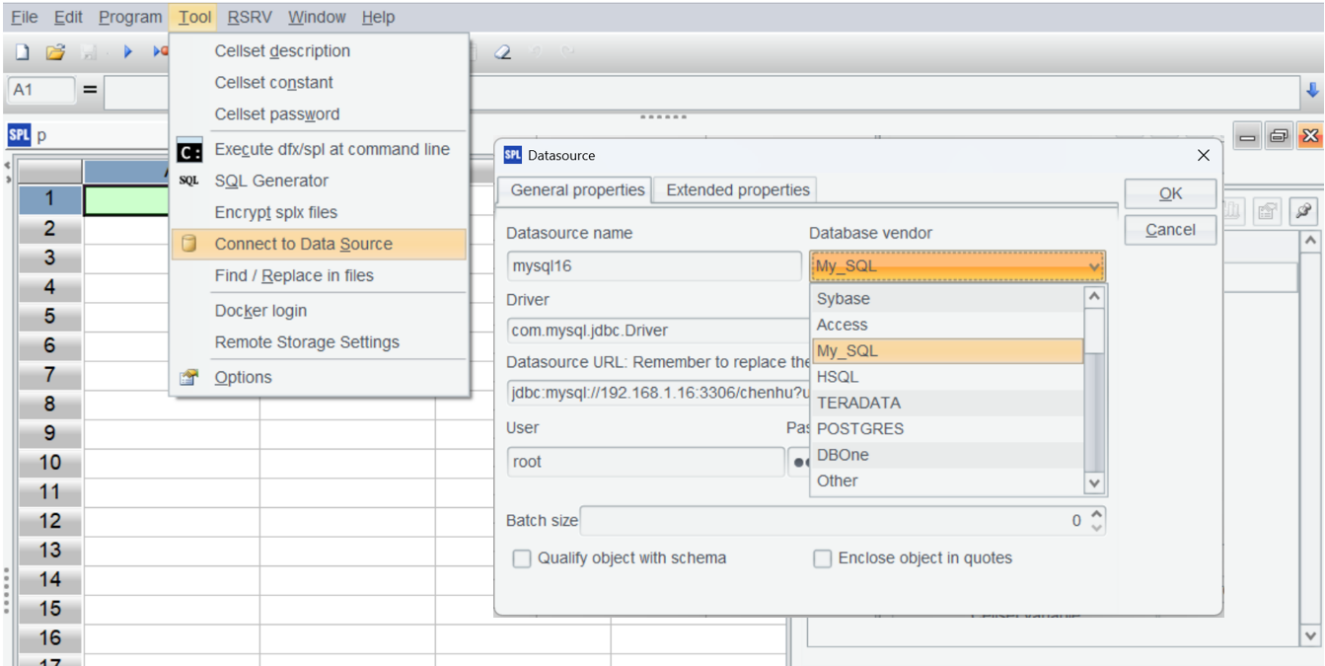
Establish a MySQL data source in esProc:
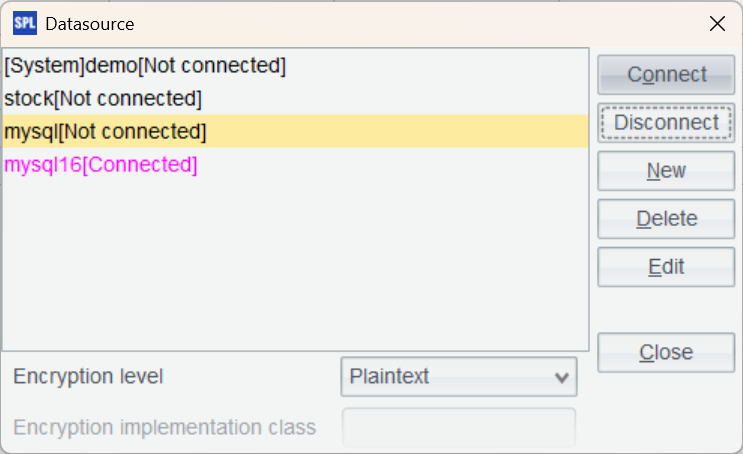
Return to the data source interface and connect to the data source we just configured. If the data source name turns pink, the configuration is successful.
Create a new script in the IDE, write SPL statements, connect to the database, and load the data of the users table using a simple SQL query:
A |
B |
|
1 |
=connect("mysql16") |
|
2 |
=A1.query@x("select user_id,event_time,event_name from events limit 100") |
|
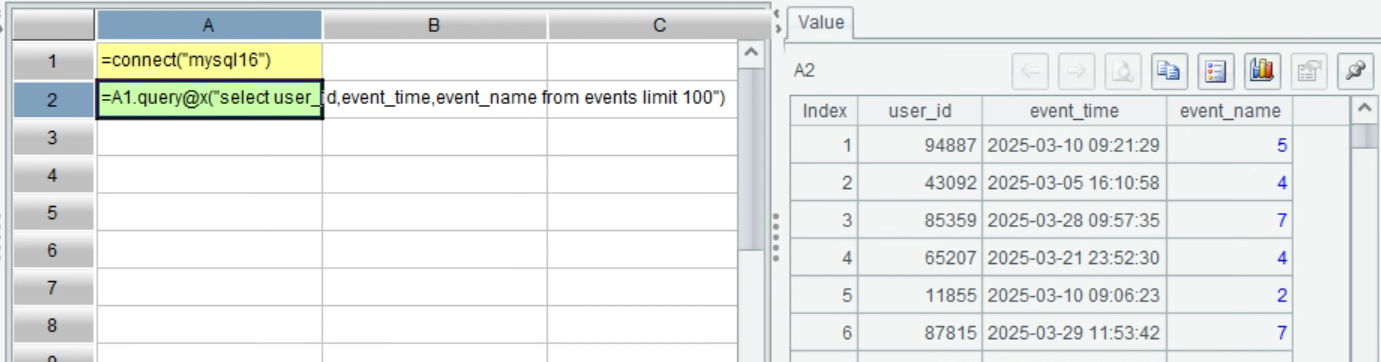
Press Ctrl+F9 to execute the script. Then, click cell A2 and click “Load data” on the right to view the first 100 rows of data:
After loading the data from the database, we can use SPL to export and store it in order:
A |
B |
|
1 |
=connect("mysql16") |
|
2 |
=A1.cursor("select user_id,event_id,event_time,event_name from events order by user_id") |
|
3 |
=file("events.ctx").create@p(#user_id,event_id,event_time,event_name) |
|
4 |
=A3.append(A2) |
>A3.close() |
5 |
>A1.close() |
|
A3 defines SPL’s composite table. The # symbol before a field indicates a dimension, which must be ordered.
In A6, the option @p of the create function indicates that the first field, user_id, is a segmentation key. This prevents records with the same user_id from being split during segmented reading.
Example 1: Let’s look at the simplest case: perform a de-duplication count on the user_id in the events table.
SQL:
select count(distinct user_id) from events;
Execution time: 16 seconds.
SPL, in contrast, uses the ordered de-duplication count syntax:
A |
|
1 |
=file("events.ctx").open().cursor@m(user_id).group@1(user_id).skip() |
Because user_id is ordered, the cursor’s group function uses an ordered grouping method to merge adjacent and identical user_id values. The @1 option indicates that only the first record of each group is taken, which avoids creating grouping subsets and improves speed.
Execution time: 0.4 seconds.
The performance advantage of SPL’s ordered de-duplication count is very significant.
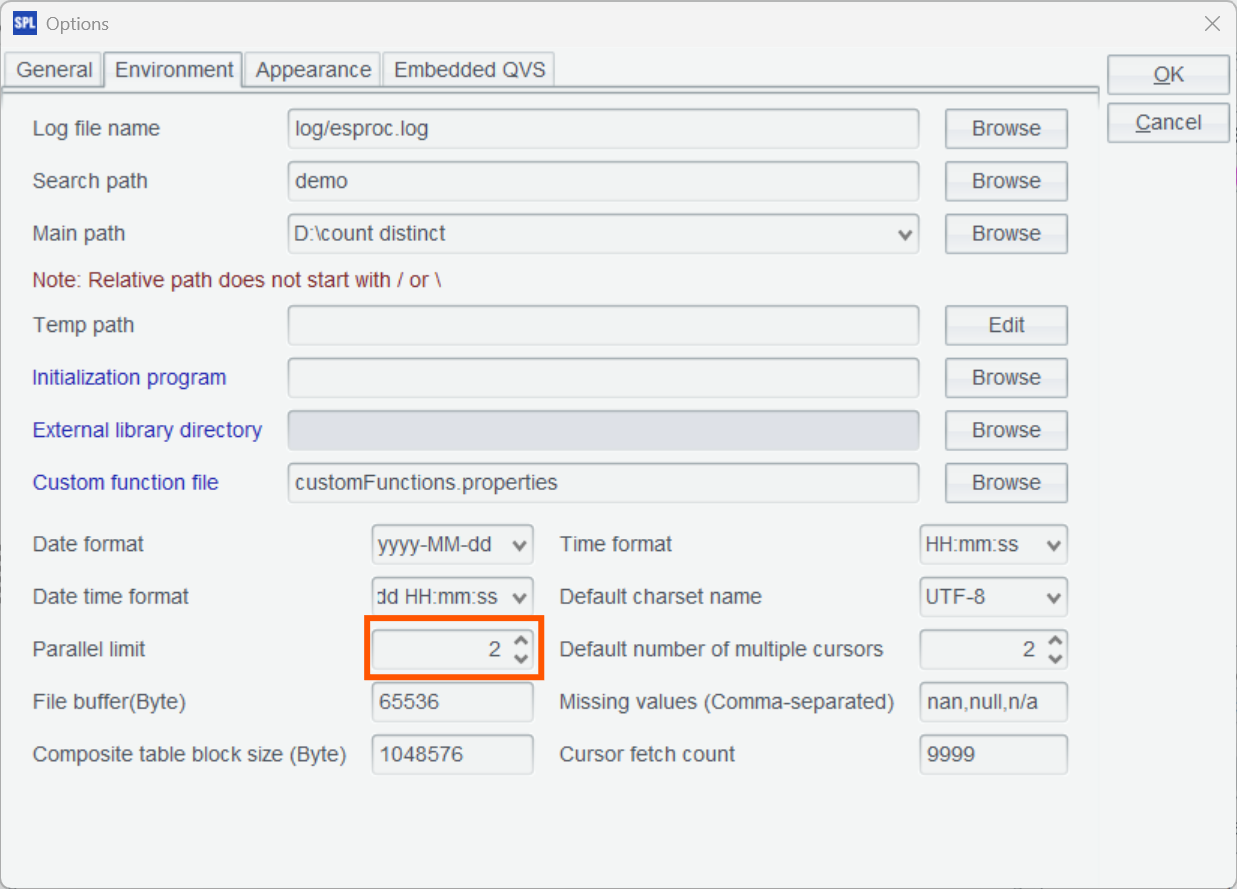
@m indicates that multi-threaded calculation is performed according to the parallel option configured in Options.
Also, enable the parallel option.
Example 2: Count the distinct number of user_ids where the event_name is either "login" or "confirm".
SQL:
select
count(distinct case when event_name = 'login' then user_id end) as count1,
count(distinct case when event_name = 'confirm' then user_id end) as count2
from
events
Execution time: 16 seconds.
SPL:
A |
|
1 |
=file("events.ctx").open().cursor@m(user_id,event_name) |
2 |
=A1.groups(;icount@o(if(event_name=="login",user_id)):count1,icount@o(if(event_name=="confirm",user_id)):count2) |
icount@o represents ordered de-duplication count.
Execution time: 0.9 seconds.
Example 3: Let’s see a more complex case. For each user, consecutive events with the same name, when ordered chronologically, are considered duplicate events. The task is to deduplicate these duplicate events and count the number of users who have more than 5 events.
The SQL is quite difficult to write, so we won’t provide it here. Interested readers can try writing it themselves.
SPL code:
A |
|
1 |
=file("events.ctx").open().cursor@m(user_id,event_name,event_time).group(user_id) |
2 |
=A1.select(~.sort(event_time).group@o1(event_name).len()>5).skip() |
The group() function, by default, creates grouping subsets.
The ~ symbol in A2 represents the current grouping subset. Because the data volume for each user_id group is not large, the whole group can be read into memory. Use the table sequence’s grouping function, group@o1, to merge adjacent and identical event_name values.
Execution time:
2 seconds.
This task is relatively complex, involving tens of millions of data records. Even on a lower-end laptop, the standard version of esProc can still achieve second-level computation speeds.
Test results:
MYSQL |
esProc |
|
Example 1 |
16 seconds |
0.4 seconds |
Example 2 |
16 seconds |
0.9 seconds |
Example 3 |
- |
2 seconds |
esProc significantly outperforms MySQL in COUNT DISTINCT calculations.
esProc’s speedup solution relies on data being stored in order by user_id. If new data contains arbitrary user_id values, it cannot be directly appended to the existing ordered data. Regenerating the full ordered data is a time-consuming process and cannot be done frequently.
In this case, the new and old data should be stored separately and orderly. After a longer interval, these data are merged regularly. For calculations such as de-duplication counts, merging the new and old data before processing enables the continued use of the quick order-based de-duplication method.
In practice, there are many calculation scenarios that involve fixed historical data, and there are also many COUNT DISTINCT calculations that urgently require acceleration. For these scenarios, using SPL’s ordered storage can effectively speed up COUNT DISTINCT operations, and the implementation is remarkably straightforward.
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version