

17. Large join query
RegisterSiteA.csv stores a large amount of registration information for an exam. candidates.csv stores a large volume of applicant information, which consists of ID, NAME, CITY and STATE. ExamLevel.txt stores arrangement of exam levels, where each state has its level and can have one level at most. Find information of applicants whose REGTIME values are between 1000 and 1100 and add SAME field in the result set to check whether they can take the exam for the level they apply for in their own state.
Expected result:
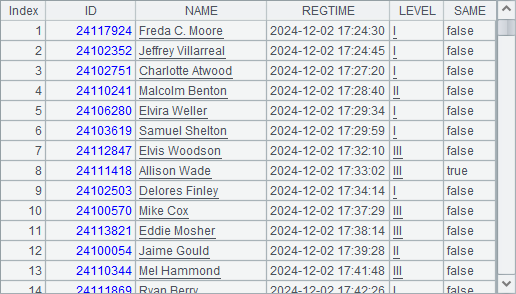
SPL code:
| A | B | C | |
|---|---|---|---|
| 1 | RegisterSiteA.csv | candidates.csv | ExamLevel.txt |
| 2 | =file(A1).cursor@ct().sortx(ID) | =file(B1).cursor@ct() | =T(C1).keys(STATE) |
| 3 | =B2.switch(STATE,C2) | ||
| 4 | =joinx(A2:Reg,ID;B3:Info,ID) | =A4.new(Reg.ID:ID, Reg.NAME:NAME, Reg.REGTIME:REGTIME, Reg.LEVEL: LEVEL, Reg.LEVEL == Info.STATE.LEVEL:SAME) | |
| 5 | =B4.sortx(REGTIME) | >A5.skip(1000) | =A5.fetch@x(100) |
A2 and B2 create cursors based on data files. To create association between the registration data and the applicant data, both need to be ordered by their joining field ID. Now data in RegisterSiteA.csv does not meet the requirement, so A2 uses cs.sortx() to sort it by ID after creating the cursor.
C2 imports data from the exam arrangement table. The table isn’t large and can be read as an in-memory table:
B3 replaces the applicant’s STATE vlaues with the exam level records to find the exam level offered by the applicant’s state.
A4 uses joinx() to join registration data cursor with applicant data cursor. Reg represents the registration data table and Info is the applicant data table. B4 prepares the result set to be returned according to A4’s result cursor. It gets values for ID, NAME, REGTIME and LEVEL from Reg, and finds if an applicant can take the exam in their own state according to whether Reg’s LEVEL value is consistent with Info’s.
As the expected final result set is required to be ordered by registration time, we need to use cs.sortx() to sort B4’s table before returning it. Note that A2 uses sort operation for executing the cursor join, but A5’s sort operation is necessary for getting the final result set correctly. But both sorting operations are computed through buffering at execution only after all involved data is obtained. This will take a lot of time.
B5 skips the first applicant 1000 records in terms of registration time. And C5 returns applicant records where REGTIME values are between 1001 and 1100.
Acutally in B3, the association between the cursor and the in-memory table only aims to get the corresponding level in the examl arrangement table. This can also be achieved through =B2.join(STATE,C2,LocalLEVEL). The code joins the cursor the in-memory table to add a new field LocalLEVEL in the cursor. In this case the judgement code for generating SAME field in B4 need to be changed to Reg.LEVEL=Info.LocalLEVEL.
18. Text search
Contents and Exercise Data
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version