

13. Text analysis using regular expression
12. Intra-group operations and rankings
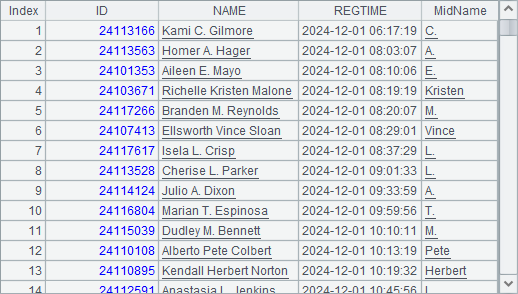
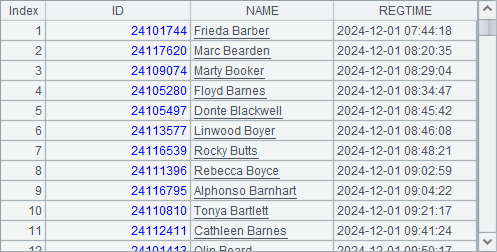
RegisterSiteA.csv stores large amount of exam registration information. (1) Find applicants who write middle names and list their middle names; and (2) Get registration information of the first 100 applicants whose last names begin with letter B.
Expected results:
SPL code:
| A | |
|---|---|
| 1 | =file(“RegisterSiteA.csv”).cursor@ct(ID,NAME,REGTIME) |
| 2 | .* (.*) .* |
| 3 | =A1.derive(NAME.regex(A2)(1):MidName) |
| 4 | =A3.select(MidName).fetch() |
| 5 | =file(“RegisterSiteA.csv”).cursor@ct(ID,NAME,REGTIME) |
| 6 | =A5.select(left(NAME.words().m(-1),1)==“B”) |
| 7 | =A5.fetch@x(100) |
A1 creates a cursor using certain fields. A2 defines a regular expression, where dot . represents any character and the parentheses means characters enclosed between two white spaces in it (if the name has the middle name, there are two white spaces) will be extracted. In A3, regex()function matches each NAME string with the regular expression and extracts the middle name to use them as values of the newly generated MidName field. A4 first gets non-null MidName values and then uses fetch() function to get the result.
A5 creates the cursor anew. Here we should not use A1.reset()function to try to use the old cursor because there are add column operation and filerting operation on the cursor. A6 selects applicants whose last names begin with letter B, during which s.words() function splits NAME string by words, A.m(-1) gets the last word, which is the last name, and left(s,n) function gets its first letter and check whether it is B. A7 fetches the required number of records from A5’s cursor. This can also be solved with regular expressions. For example, change the code in A6 to =A5.select(NAME.regex(“.* (B)[A-za-z]*$”)(1)). In the regular expression, [A-Za-z] indicates any English letter, and $ indicates the end of a string.
14. Computations according to intervals
Contents and Exercise Data
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version