

9. Cursor merge
8. Using cursor on large data sets
RegisterSiteA.csv, RegisterSiteB.csv and RegisterSiteC.csv store large amounts of exam registration information ordered by registration time REGTIME. (1) Get registration records where REGTIME values are between 101 and 200; (2) Get records where IDs are within 24110001~24110100; and (3) Find the actual number people who have registered and list records of people who register repeatedly.
Expected results:
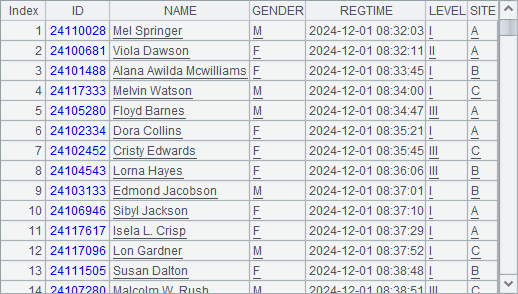
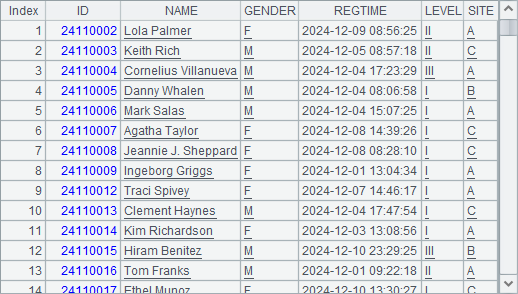

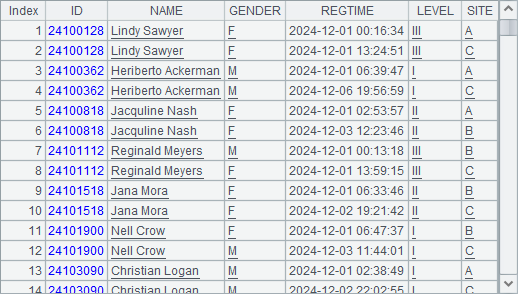
SPL code:
| A | B | C | |
|---|---|---|---|
| 1 | RegisterSiteA.csv | RegisterSiteB.csv | RegisterSiteC.csv |
| 2 | =[A1:C1].(file(~).cursor@ct()) | ||
| 3 | =A2.merge(REGTIME) | =A3.skip(100) | =A3.fetch(100) |
| 4 | >A2.(~.reset()) | ||
| 5 | =A2.(~.sortx(ID)).merge@u(ID) | =A5.skip(;between(ID, 24110001:24110100)) | =A5.fetch@x(;ID>24110100) |
| 6 | >A2.(~.reset()) | =A2.merge(REGTIME).groups(; count(~):Count,icount(ID):ICount) | |
| 7 | >A2.(~.reset()) | ||
| 8 | =A2.(~.sortx(ID)).merge(ID) | =A8.select(ID==ID[-1] || ID==ID[1]) | =B8.fetch() |
A2 generates a sequence of cursors based on the three files. In A3, CS.merge() function performs merge on the sequence of cursors. The merged cursors have similar uses as an originally single cursor, on which skip, fetch and other operations can be performed. B3 skips the first 100 records, and C3 gets records whose registration time values are within 101~200. As the result set shows, registrations occur in different sites but records are arranged by registrarion time.
To go on to perform the other queries, we need to turn back the file cursor – As A4 does. In order to query registration information according to ID, we need to sort every cursor using cs.sortx()before merging those cursors – As A5 does. CS.merge() function works with @u option to exclude duplicate records having same IDs. B5 executes cs.skip(;x) function to skip records that do not correspond to the specified data interval. Then in C5 cs.fetch(;x) function fetches data from the cursor until expression x becomes true to get registration records corresponding to the given range of IDs.
B6 still queries data from the merged cursor while performing aggregation on the whole data. Through comparison we find there are indeed repeated registrations.
A8 merges cursors according to ID. B8 selects every record whose ID is the same as those of records before and after it through cross-row comparisons, which compare IDs only and ignore the other field values. And C8 gets records having repeated registrations by fetching data from B8.
10. Cumulative sum query
Contents and Exercise Data
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version