

2. Test data preparation
1. Data retrieval and analysis
Create a new data table and store it in EmpInfo.txt. The table has five fields: ID field is the primay key, which contains natural numbers used as sequence numbers; Name field contains employee names; Gender field is the gender; and Birthday field contains birth dates. It has 1000 randomly generated records. Name values are generated according to three files – Top500MaleNames.txt, Top500FemaleNames.txt and Top500Surnames.txt. Gender values, where men and women each account for about half, are M or F, which is generated randomly. Birthday values are random dates between 1990 and 2005. Then read data from the file as a table sequence. Two requirements for preparing the test data: (1) use for loop to generate data; (2) use subroutines in the loop to generate data.
Expected result set:
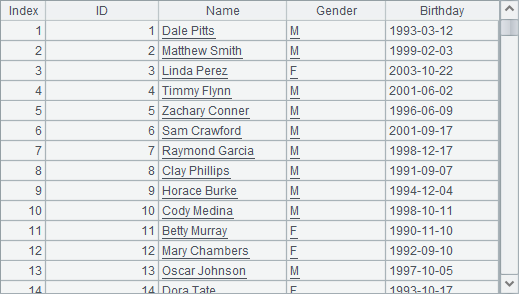
SPL code:
(1)
| A | B | C | |
|---|---|---|---|
| 1 | 1000 | 500 | |
| 2 | =create(ID, Name, Gender, Birthday) | ||
| 3 | =file(“Top500MaleNames.txt”).import@i() | =file(“Top500FemaleNames.txt”).import@i() | =file(“Top500Surnames.txt”).import@i() |
| 4 | 1990-1-1 | 2006-1-1 | =B4-A4 |
| 5 | for A1 | =rands(“MF”,1) | =C3(rand(B1)+1) |
| 6 | if B5==“M” | >name=A3(rand(B1)+1) | |
| 7 | else | >name=B3(rand(B1)+1) | |
| 8 | =A4+rand(C4) | >A2.insert(0, A5, name+" " +C5, B5, B8) | |
| 9 | =file(“EmpInfo.txt”) | >A9.export@t(A2) | =A9.import@t() |
A1 defines the number of records to be generated, and B1 records the number of names and surnames in the database. A2 creates an empty table sequence. Line 3 reads information from the database. To import the one-column table data as a sequence, use @i option in the function. Line 4 computes the number of days between the starting date and the ending date for generating birthdays randomly. A5 performs for loop to generate one record at one time, during which B5 randomly selects a letter between M and F and makes it gender value, C5 randomly selects a Surname, C6 and C7 respectively set a random Firstname to variable name according to gender. B8 randomly generates a birthday. C8 inserts a new record to A2’s table sequence according to the newly generated information. When the loop is finished, B9 exports data in A2’s table sequence to a file. We can also use T()function to save the data in a file. Then the code in B9 will be >T(“EmpInfo.txt”:A2). C9 returns the data retrieval result set, which is the same as A2’s result set.
(2)
| A | B | C | |
|---|---|---|---|
| 1 | 1000 | 500 | 0 |
| 2 | =create(ID, Name, Gender, Birthday) | ||
| 3 | =file(“Top500MaleNames.txt”).import@i() | =file(“Top500FemaleNames.txt”).import@i() | =file(“Top500Surnames.txt”).import@i() |
| 4 | 1990-1-1 | 2006-1-1 | =B4-A4 |
| 5 | >A1.(newRec()) | ||
| 6 | func newRec() | =rands(“MF”,1) | =C3(func(A10, B1)) |
| 7 | if B6==“M” | >name=A3(func(A10, B1)) | |
| 8 | else | >name=B3(func(A10, B1)) | |
| 9 | =A4+rand(C4) | >A2.insert(0, C1=C1+1, name+" " +C6, B6, B9) | |
| 10 | func | =rand(A10) | =B10*B10\A10+1 |
| 11 | =file(“EmpInfo.txt”) | >A11.export@t(A2) | =A11.import@t() |
The first four lines are the same as those in the first script. A5 recursively calls A6’s subfunction newRec() the number of times equal to the target number of records. The code in lines 6~9 starts from A6’s subroutine, where the subfunction is named newRec and which generates a new record randomly to insert to A2’s table sequence. In particular A10’s subroutine is called to randomly generate sequence numbers of names. The range of the random sequence numbers is defined as a parameter for the call. Line 10 is another subroutine starting from A10. This subroutine tunes the selection probability by x2/n to let names in the front part become more likely to be selected when it selects sequence numbers of names randomly. Parameters passed to the subroutine will be filled into the starting cell, and their values can be utilized in the computation. If there is more than one parameter, they will be sequentially filled into cells to the right of the starting cell. In such cases, it is important to ensure that these adjacent cells are left vacant to accommodate the additional parameters.
3. Pivot
Contents and Exercise Data
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version