

Practice #6: Conditional Filtering by Enumerated Field
An enumerated field has only several values. The format of filtering condition specified on an enumerated field (f) can be f =v1 or f=v2 or…, f !=v1 and f !=v2 and…, in or not in. The database compares f with n values. When the data table is large, there is a great number of comparisons, resulting in low performance. The larger the value of n, the lower the performance.
If no comparisons are involved for performing the filtering operation, the performance will become much higher. esProc SPL offers alignment sequence mechanism to achieve that target.
Take the orders table to look at how to use the alignment sequence. First, determine the range of values in an enumerated filed. customer_id field has a corresponding dimension table and its value range can be determined. Neither employee_id field nor employee_name field have a corresponding dimension table, and a pre-traversal of the fact table orders is needed to determine their value ranges and generate dimension tables. Here we suppose there isn’t the employee_id field and there aren’t employees having same names.
In the preceding three practices, dimension table employee.btx is already generated, orders table can be replaced by ordersQ3.ctx, and employee table is numberized.
Example 6.1 Find orders records where employee name is name10 or name101 and count the number of orders by date.
select order_date,count(1)
from orders
where
employee_name='name10' or employee_name='name101'
group by order_date;
It takes 20 seconds to finish executing the code.
SPL code example 27:
A |
|
1 |
=now() |
2 |
=file("employeeQ6.btx").import@b() |
3 |
=A2.(["name10","name101"].contain(employee_name)) |
4 |
=file("ordersQ6.ctx").open().cursor@m(order_date;A3(employee_num)) |
5 |
=A4.groups(order_date;count(1)) |
6 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
It takes 0.1 second to finish executing the SPL script.
Let’s focus on A3, which generates an alignment sequence according to the filtering condition:
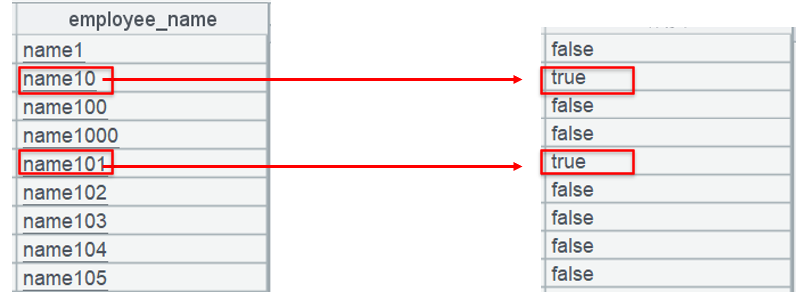
In the figure, the table on the left is employee and that on the right is the alignment sequence.
The alignment sequence is a boolean sequence having the same length as the dimension table employee. contain()function judges whether sequence [“name10”,“name101”] includes the name value at the current position. If it includes the value, assign true to the member in the alignment sequence at the corresponding position; otherwise assign false to it.
A4 performs select target records with the alignment sequence:
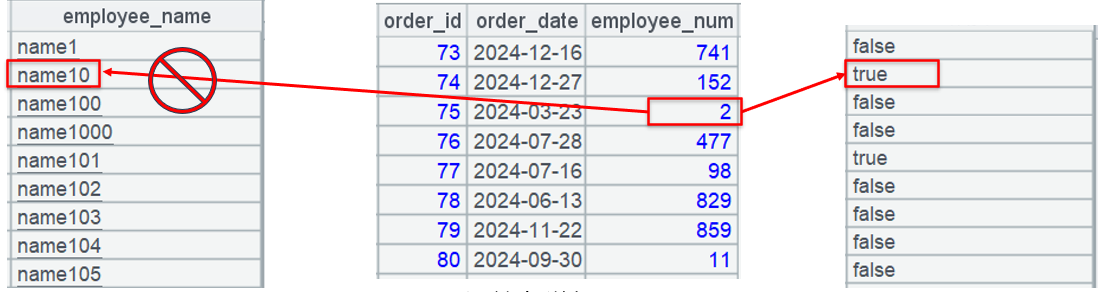
To perform filtering on orders table (the one in the middle), the regular method is to get employee name at the corresponding position from employee table (the one on the left) according to employee_num value and to compare the current name with sequence [“name10”,“name101”].
SPL takes a different route. It gets the boolean value at the corresponding position from the alignment sequence (the one on the right) according to employee number; if it is true the condition is met, otherwise the condition isn’t met. In this way, the comparison operation is transformed to an operation of position-based member retrieval from a sequence and there is no need to compare employee name anymore.
Below is the script that does not use the alignment sequence mechanism.
SPL code example 28:
A |
|
1 |
=now() |
2 |
=file("ordersQ6.ctx").open().cursor@m(order_date;employee_name=="name10" || employee_name=="name101") |
3 |
=A2.groups(order_date;count(1)) |
4 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
A2 matches two strings to perform the conditional filtering.
It takes 0.1 second to finish executing the SPL script.
Example 6.2 Find orders records containing 10 employee names, including name10 and so on, and count orders by date.
The SQL code will be lengthy if the OR keywork is used, we use the IN operator:
select order_date,count(1)
from orders
where
employee_name in ('name10' , 'name101',…)
group by order_date;
It takes 16 seconds to finish executing the SQL code.
SPL code example 29: With the alignment sequence.
A |
|
1 |
=now() |
2 |
=file("employeeQ6.btx").import@b() |
3 |
=A2.(["name10","name101",…].contain(employee_name)) |
4 |
=file("ordersQ6.ctx").open().cursor@m(order_date;A3(employee_num)) |
5 |
=A4.groups(order_date;count(1)) |
6 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
It takes 0.15 second to finish executing the SPL script.
Just add employee names to the code if there are more to be compared.
SPL code example 30: Without the alignment sequence.
A |
|
1 |
=now() |
2 |
=["name10", "name101", …].sort() |
3 |
=file("ordersQ6.ctx").open().cursor@m(order_date;A2.contain@b(employee_name)) |
4 |
=A3.groups(order_date;count(1)) |
5 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
It takes 0.18 second to finish executing the SPL script.
Example 6.3 Find orders records where the corresponding customer’s city ID is 35 and compute the total freight.
SQL involves subqueries:
select sum(shipping_fee)
from orders
where
customer_id in (
select customer_id
from customer
where city_id=35);
It takes 13 seconds to finish executing the SQL code.
SPL code example 31: With the alignment sequence.
A |
|
1 |
=now() |
2 |
=file("customerQ6.btx").import@b() |
3 |
=A2.(city_id==35) |
4 |
=file("ordersQ6.ctx").open().cursor@m(shipping_fee;A3(customer_num) ) |
5 |
=A4.total(sum(shipping_fee)) |
6 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
It takes 0.1 second to finish executing the SPL script.
SPL code example 32: Without the alignment sequence.
A |
|
1 |
=now() |
2 |
=file("customerQ6.btx").import@b().keys@i(customer_id) |
3 |
=A2.select@i(city_id==35) |
4 |
=file("ordersQ6.ctx").open().cursor@m(shipping_fee;customer_id:A3) |
5 |
=A4.total(sum(shipping_fee)) |
It takes 0.1 second to finish executing the SPL script.
There is no noticeable difference in time spent in performing search and computation by primary key cutomer_id and search by position spend.
Performance summary (unit: second):
MYSQL |
SPL alignment sequence |
SPL without alignment sequence |
|
Example 6.1 |
20 |
0.1 |
0.1 |
Example 6.2 |
16 |
0.15 |
0.18 |
Example 6.3 |
13 |
0.1 |
0.1 |
Exercises:
1. Find orders records where corresponding customer’s city IDs are 3 and get the total count of orders.
2. Critical thinking: Do you ever encounter any large table filtering computation by an enumerated filed in one of your familiar databases? Can you use the alignment sequence mechanism to speed up the computation?
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL

