

Practice #4: Large Primary-Subtable Join
This section focuses on the speed-up of primary key-based joins.
The association between the primary table (orders) and its subtable (details) is primary-key based. Still, SQL uses JOIN to achieve such association. When both tables are large, often the computing speed becomes very slow.
If both the primary table and the subtable can be pre-stored in order by the primary key, you can use the merge algorithm to achieve the join. Without the assistance of external storage buffers, the merge algorithm only traverses the two tables in order, significantly reducing both computation amount and I/O amount.
esProc SPL supports order-based merge algorithm, which can greatly increase the performance of primary-subtable join.
First, prepare the data – export the historical data from the database to CTX files. Define Q4.etl in ETL:
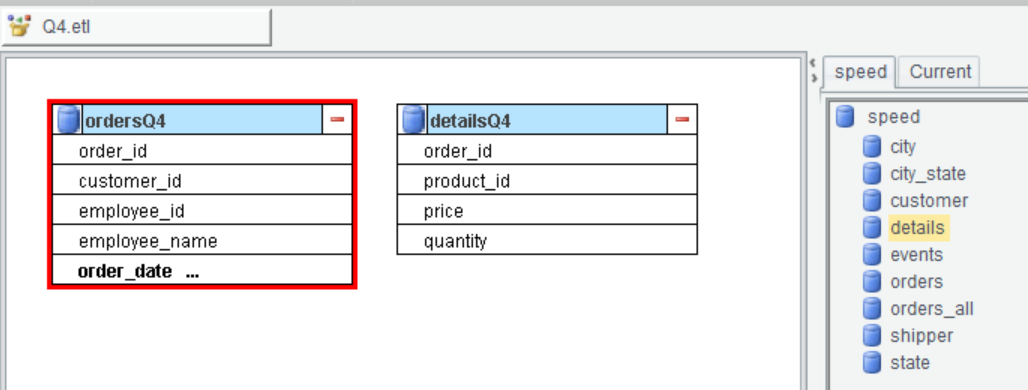
Add Q4 to the name of each of the two tables.
Divide table detailsQ4 into multiple segments by the first field:
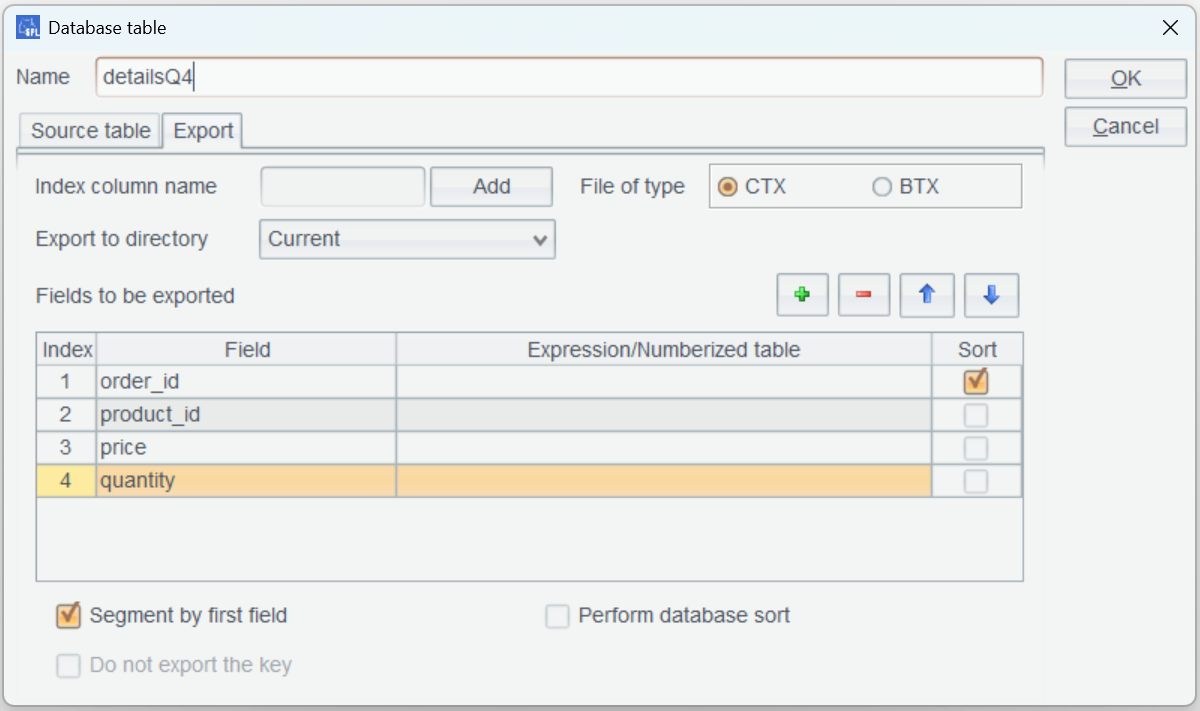
As there are duplicates in order_id values of table detailsQ4, you need to declare that the first field is the segmentation key.
In case that records having same order_id value are divided and put in two different segments, @p option will be automatically added to create() function in the SPLX file.
Note: The two tables are joined on order_id, so they are stored in order according to this field. There is no need to check “Perform database sort”.
SPL code example 18:
A |
|
1 |
=connect("speed") |
2 |
="d:\\speed\\etl\\" |
3 |
=A1.cursor("SELECT order_id,customer_id,employee_id,employee_name,order_date,shipper_id,shipping_fee,shipping_address FROM orders") |
4 |
=A3.sortx(order_id) |
5 |
=file(A2+"ordersQ4.ctx").create@y(#order_id,customer_id,employee_id,employee_name,order_date,shipper_id,shipping_fee,shipping_address).append(A4).close() |
6 |
=A1.cursor("SELECT order_id,product_id,price,quantity FROM details") |
7 |
=A6.sortx(order_id) |
8 |
=file(A2+"detailsQ4.ctx").create@yp(#order_id,product_id,price,quantity).append(A7).close() |
9 |
=A1.close() |
A5 and A8 use #order_id to declare that the CTX file is ordered by order_id.
For details table, A8 automatically uses @p option in create() function to specify the first field as the segmentation key to prevent records of same order_id value from being separated and put into two different segments.
Example 4.1 Within a specified time interval, group records by customer and compute order amount in each group.
select
o.customer_id,sum(d.quantity * d.price)
from
orders o
join
details d on o.order_id = d.order_id
where o.order_date>='2024-01-15'
and o.order_date<='2024-03-15'
group by o.customer_id;
It takes 25 seconds to finish executing the SQL code.
SPL code example 19:
A |
|
1 |
=now() |
2 |
=file("ordersQ4.ctx").open().cursor@m(order_id,customer_id;order_date>=date(2024,1,15) && order_date<=date(2024,3,15)) |
3 |
=file("detailsQ4.ctx").open().cursor(order_id,quantity,price;;A2) |
4 |
=joinx(A2:o,order_id;A3:d,order_id) |
5 |
=A4.groups(o.customer_id;sum(d.quantity*d.price)) |
6 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
It only takes one second to finish executing the SPL script.
In A3, the last parameter of the cursor() function is A2, which means multithreaded processing. To perform the multithreaded processing, details table will be also segmented by aligning with the orders table, ensuring that the two tables can be merged in order correctly.
A4 performs order-based merge on orders and details.
A5 performs grouping & aggregation on the merge result set.
Let’s look at A4:

joinx() function merges orders and details in order and returns a two-field cursor. As can be seen from the above figure each field value in the cursor is a record object.
You also need to note that the two tables have a one-to-many relationship, which means orders records will be repeatedly copied.
Example 4.2 Group order records where customer ID 3 or 9 by product ID and compute order amount in each group.
select
d.product_id,sum(d.quantity * d.price)
from
orders o
join
details d on o.order_id = d.order_id
where o.customer_id =3
or o.customer_id=9
group by d.product_id;
It takes 21 seconds to finish executing the above code.
SPL code example 20:
A |
|
1 |
=now() |
2 |
=file("ordersQ4.ctx").open().cursor@m(order_id;customer_id==3 || customer_id==9) |
3 |
=file("detailsQ4.ctx").open().cursor(order_id,quantity,price,product_id;;A2) |
4 |
=joinx(A2:o,order_id;A3:d,order_id) |
5 |
=A4.groups(d.product_id;sum(d.quantity*d.price)) |
6 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
It takes 0.6 second to finish executing the SPL script.
Example 4.3 Compute the average amount of all orders. Requirement: Get order detail records whose product IDs aren’t 2 and 8, group them by date, and find the average order amount in each group. Note: Count unique orders in each group.
select
o.order_date,sum(d.quantity * d.price)/count(distinct o.order_id)
from
orders o
join
details d on o.order_id = d.order_id
where d.product_id !=2
and d.product_id !=8
group by o.order_date;
It takes 40 seconds to finish executing the above code. First primary-subtable join and then distinct count, but in SQL both operations have low performance.
SPL code example 21:
A |
|
1 |
=now() |
2 |
=file("ordersQ4.ctx").open().cursor@m(order_id,order_date) |
3 |
=file("detailsQ4.ctx").open().cursor(order_id,quantity,price;product_id!=2 && product_id!=8;A2) |
4 |
=joinx(A2:o,order_id;A3:d,order_id) |
5 |
=A4.groups(o.order_date;sum(d.quantity*d.price)/icount@o(o.order_id)) |
6 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
SPL’s order-based distinct count has much higher performance. Specifically speaking, the algorithm requires that records are ordered by order_id and can be implemented after records are merged in order.
It takes 1.5 seconds to finish executing SPL script.
Performance summary (unit:second):
MYSQL |
SPL |
|
Example 4.1 |
25 |
1 |
Example 4.2 |
21 |
0.6 |
Example 4.3 |
40 |
1.5 |
Exercises:
1. Get order details records where product IDs are 3 or 6, group them by customer ID, and compute average order amount in each group.
2. Critical thinking: Do you ever encounter large primary-subtable joins in your familiar databases? Can you use the order-based merge algorithm to speed up the joins?
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL

