

Practice#2: COUNT DISTINCT
SQL COUNT DISTINCT has been slow. It is, in essence, a grouping operation, which keeps traversed grouping field values for later comparisons. When the result set is too large, the data needs to be written to the hard disk and buffered, resulting in low performance.
If data is sorted by the deduplication field, computing ordered COUNT DISTINCT becomes much simpler – during traversal you just need to record the field value different from the preceding one and add 1 to the count, without the need to retain the result set and buffer data to the external storage.
But databases can’t ensure that data is ordered, so it is difficult to implement the order-based COUNT DISTINCT. esProc SPL can store data in order after they are exported, achieving high-performance order-based COUNT DISTINCT.
Take event table (events) as an example. It has data as follows:
event_type is the type of action. For example, 1 represents login, 2 represents view, …, and 7 represents confirm.
Analyses and computations on an event table are generally DISTINCT operation or COUNT DISTINCT operation on user ID. When data is written to the external storage, they should be stored in order by user ID. During that process, order-based DISTINCT can be used to boost performance.
Let’s define a new etl file named Q2.etl. Repeat the steps performed above – connect to database, drag events table in, and edit the settings:
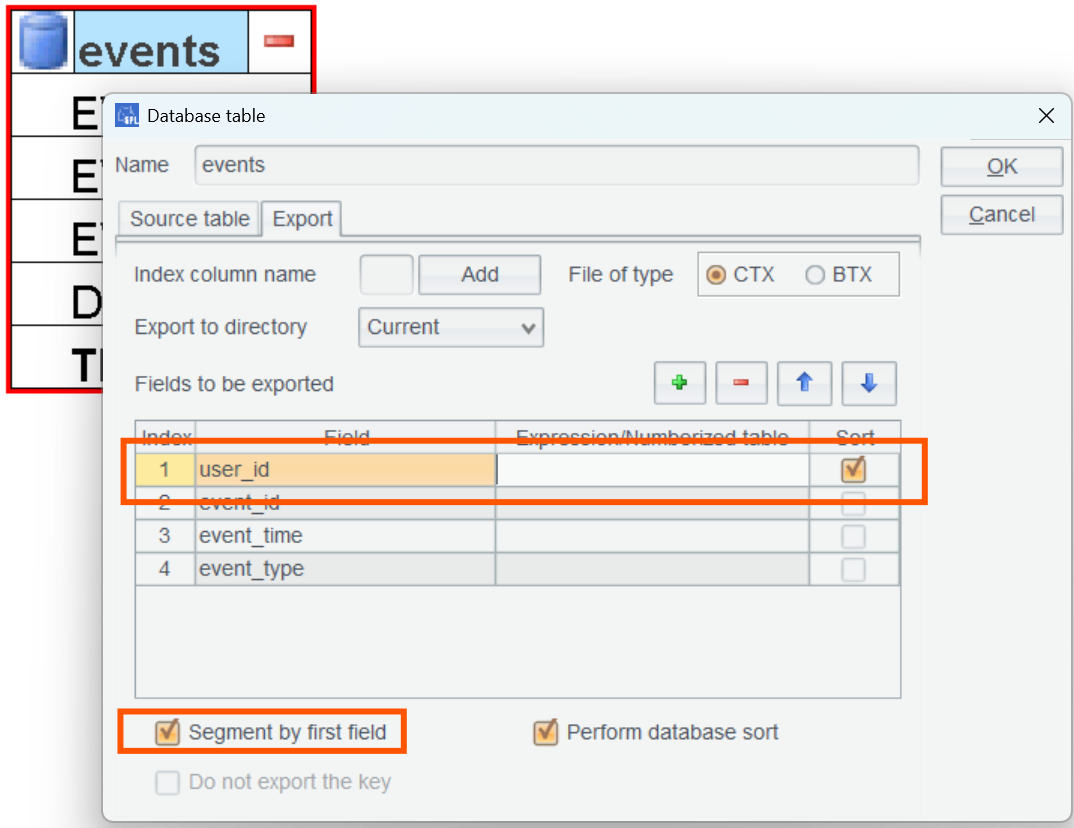
Here data is stored in order according to the customer ID so that order-based DISTINCT can be used to improve performance. The sorting field must be placed at the beginning.
As user_id values are not unique, option “Segment by first field” should be checked, meaning the first field will be the segmentation field.
To prevent records corresponding to the same user_id value are put into two different segments during segmental retrieval, the create() function in SPLX will be automatically attached with an @p option.
Check “Perform database sort” when the database currently used has good performance. If the option isn’t checked, data will be sorted in SPL.
Note: As there is a namesake MySQL system table, useless fields will be removed from the events table in ETL by not retrieving them.
Code example 9 - Export SPL via the ETL tool: Dump data to a CTX composite table.
A |
|
1 |
=connect("speed") |
2 |
="d:\\speed\\etl\\" |
3 |
=A1.cursor("SELECT event_id,user_id,event_time,event_type FROM events ORDER BY user_id") |
4 |
=A3.new(user_id,event_id,event_time,event_type) |
5 |
=file(A2+"events.ctx").create@yp(#user_id,event_id,event_time,event_type).append(A4).close() |
6 |
=A1.close() |
A3’s statement must contain order by user_id.
To create a composite table, A5 uses #user_id to declare that the composite table will be ordered by this field. Here @p option is automatically added.
What does data ordered by user look like? Below shows them intuitively.
Execute the following SPL code example 10:
A |
|
1 |
=file("events.ctx").open().cursor().fetch(1000) |
In the right part of the IDE, you can see that:
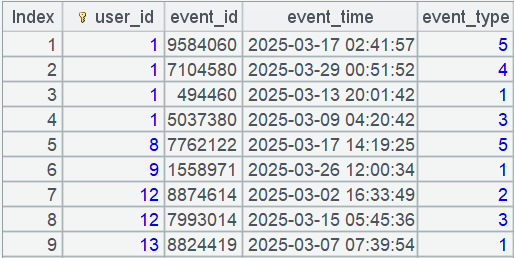
Records of each user are continuously stored, and retrieval of them is also continuous.
The number of each user’s records is not big. The data can all be loaded into the memory for performing complicated computations.
Example 2.1: Find the number of unique users in table events.
SQL statement for doing this:
select count(distinct user_id) from events;
It takes 7 seconds to finish executing the SQL statement.
SPL count distinct method:
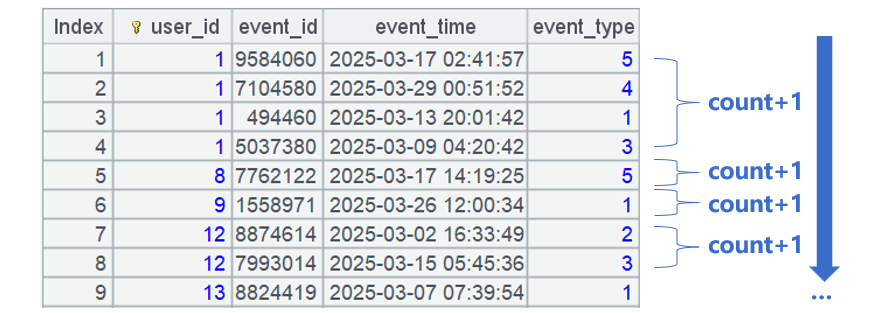
To perform count distinct, just combine user records that are neighbors and where user ids are same.
In addition, if you only need the total count and do not need the grouping & aggregation, you can choose not to group records by user_id field to generate the subsets so that the performance will be better.
SPL code example 11:
A |
|
1 |
=now() |
2 |
=file("events.ctx").open().cursor@m(user_id).group@1(user_id).skip() |
3 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
In A2, the group()function under cursor() performs order-based grouping operation to combine neighboring records having same user_id value.
@1 used in group() function retrieves the first record from each group, making it unnecessary to generate the grouped subsets.
With this algorithm, it takes 0.1 second to finish executing the script.
Example 2.2: Find the number of user IDs (user_id) that perform login action or confirm action.
event_type value 1 means login, and event_type value 7 means confirm.
SQL statement:
select
count(distinct case when event_type = 1 then user_id end) as count1,
count(distinct case when event_type = 7 then user_id end) as count2
from
events;
It takes 5 seconds to finish executing the SQL statement.
SPL code example 12:
A |
|
1 |
=now() |
2 |
=file("events.ctx").open().cursor@m(user_id,event_type) |
3 |
=A2.groups(;icount@o(if(event_type==1,user_id)):count1,icount@o(if(event_type==7,user_id)):count2) |
4 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
icount() function performs COUNT DISTINCT operation. It works with @o option to perform order-based COUNT DISTINCT, which also combine neighboring records having same event type.
If the condition if(event_type==1,user_id)):count1 holds, add the current user_id value to the count; if the condition does not hold, the result is null.
icount()function ignores null members. [1,null,1,2,3].icount@o(), for example, gets the result 3.
It takes 0.15 second to finish executing the script.
Example 2.3: Find the number of users who correspond to more than 5 events after duplicate events are removed.
For a same user, an event – when compared with the preceding one – that happens in chronological order and has the same event_type value are the duplicate one. For example, user 31 has an event whose type is 7, the directly next event whose type is also 7 is a duplicate:
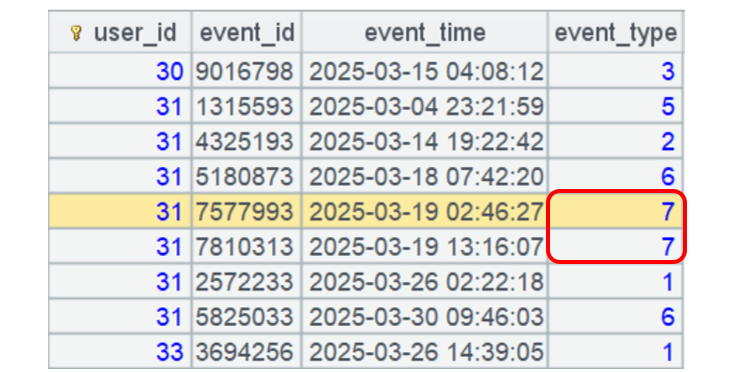
It is difficult to write code in SQL to get this done. Try writing it if you are interested.
SPL code example 13:
A |
|
1 |
=now() |
2 |
=file("events.ctx").open().cursor@m(user_id,event_type,event_time).group(user_id) |
3 |
=A2.select(~.sort(event_time).group@o1(event_type).len()>5).skip() |
4 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
It takes 0.5 second to finish executing the script.
In A2, the group()function under cursor() does not have any options and thus generates grouped subsets by default. In A3, ~ represents the current grouped subset.
Let’s look at A3’s statement. The data amount in each user_id group is not large, and can be wholly loaded to the memory to form table sequence ~. Below is one of the groups:
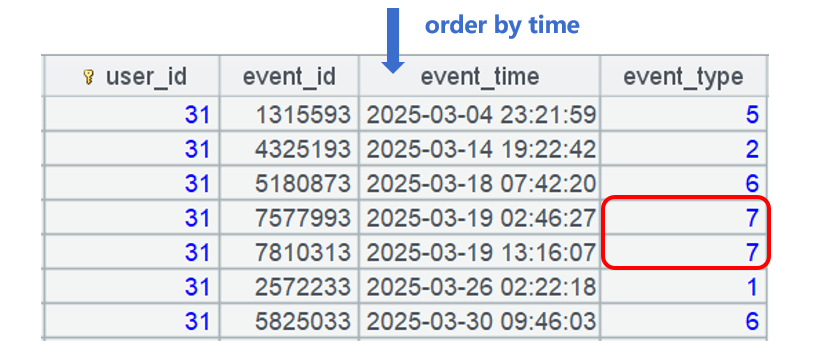
After ~.sort(event_time) sorts table sequence ~ by event time, duplicates are a record’s neighbors having same event_type value(s). Then perform grouping operation group@o1 on this table sequence to merge neighboring records having same event_type value so that the duplicates are removed.
Performance summary (unit:second):
MYSQL |
SPL |
|
Example 2.1 |
7 |
0.1 |
Example 2.2 |
5 |
0.15 |
Example 2.3 |
Hard to implement |
0.5 |
Exercises:
1. Find the number of unique user IDs under which no login action or confirm action occurs.
2. Critical thinking: Have you ever encounter cases where the DISTINCT operation or COUNT DISTINCT operation is very slow? Do they become faster when the order-based DISTINCT algorithm is used?
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL

