

How to Speed Up EXISTS in Primary-Subtable Joins with esProc
In databases, EXISTS operations between large primary and sub tables often result in poor performance. Such operations are essentially join operations. If the primary and sub tables are pre-sorted by their primary keys, the ordered merge algorithm can be employed to significantly improve performance. This algorithm requires only sequential traversal of the two tables, eliminating external storage buffering and drastically reducing I/O and computation.
esProc supports the ordered merge algorithm, allowing it to transform EXISTS operations on primary and sub tables into ordered merges, thereby significantly improving computational performance.
Below, we will use the example of orders and order details tables to compare the performance of esProc SPL and MySQL in calculating EXISTS and NOT EXISTS for primary-subtable joins.
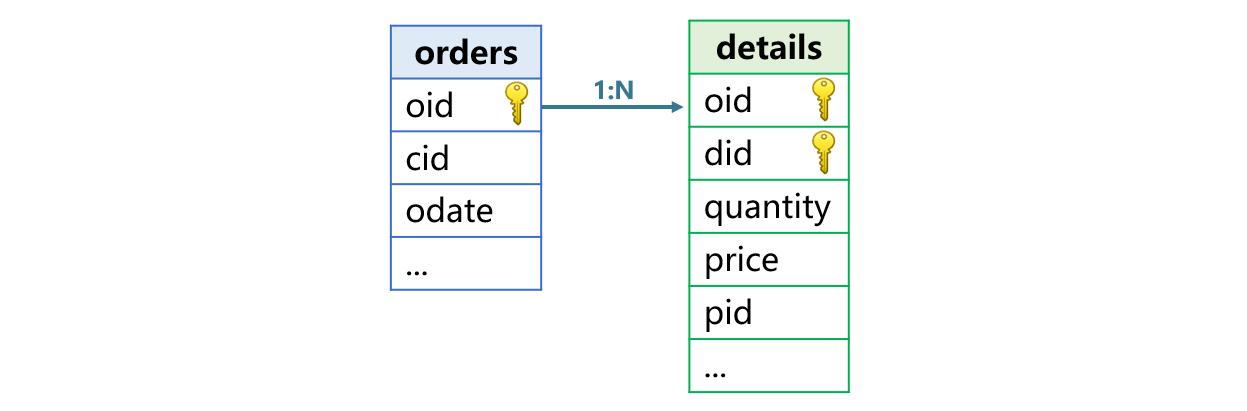
In the MYSQL database, the orders table (10 million records) stores all orders for 2024, with oid (order ID) as the primary key, and fields including cid (customer ID) and odate (order date). The details table (30 million records) uses a composite primary key of oid and did (detail ID) and includes fields quantity, price, and pid (product ID).
Test environment: VMware virtual machine with the following specifications: 8-core CPU, 8GB RAM, SSD. Operating system: Windows 11. MySQL version: 8.0.
First, download esProc at https://www.esproc.com/download-esproc/. The standard version is sufficient.
After installing esProc, test whether the IDE can access the database normally. First, place the JDBC driver of the MySQL database in the directory ‘[Installation Directory]\common\jdbc,’ which is one of esProc’s classpath directories.

Establish a MySQL data source in esProc:
Return to the data source interface and connect to the data source we just configured. If the data source name turns pink, the configuration is successful.
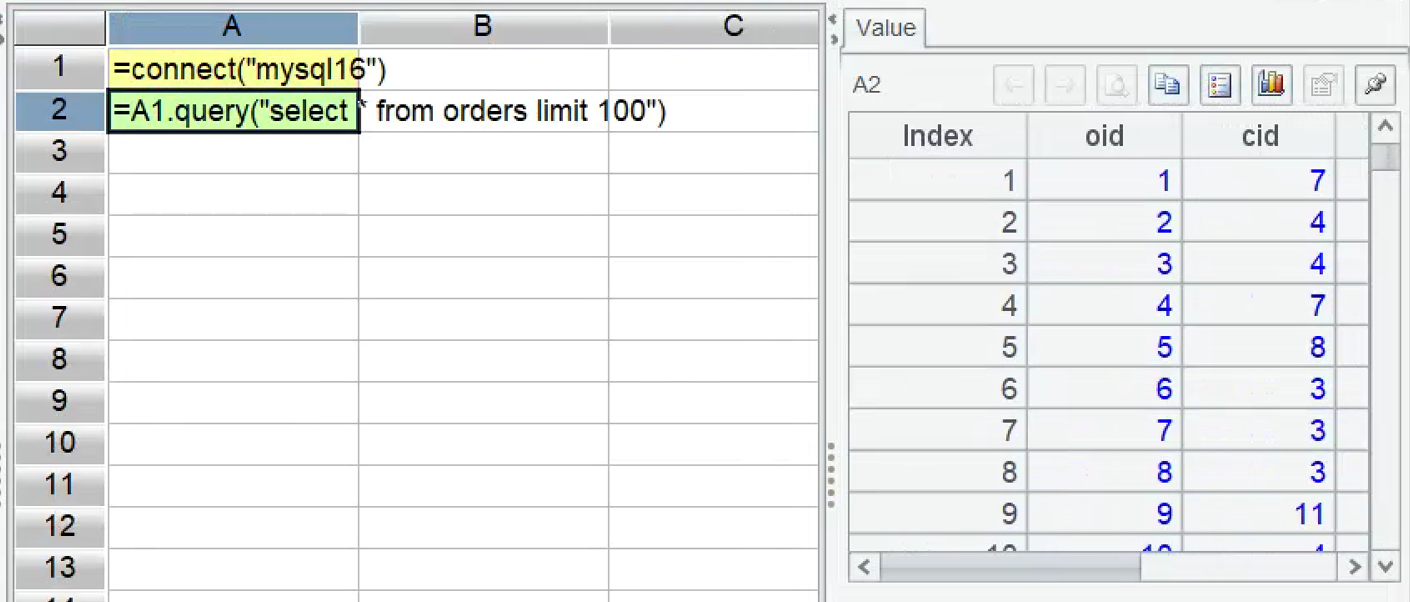
In the IDE, create a new script, write SPL statements to connect to the database, and execute a SQL query to load part of the data from the orders table.
A |
B |
|
1 |
=connect("mysql16") |
|
2 |
=A1.query("select * from orders limit 100") |
|
Press Ctrl+F9 to execute the script. The result of A2 is displayed on the right side of the IDE, which is very convenient.
Next, prepare the data by exporting the historical data from the database to esProc’s high-performance files.
A |
|
1 |
=connect("mysql16") |
2 |
=A1.cursor("select oid,cid,eid from orders order by oid") |
3 |
=file("orders.ctx").create(#oid,cid,eid) |
4 |
=A3.append(A1) |
5 |
=A1.query("select oid,did,quantity,price from details order by oid") |
6 |
=file("details.ctx").create@p(#oid,did,quantity,price) |
7 |
=A6.append(A5) |
8 |
>A1.close(),A3.close(),A6.close() |
A2 generates a database cursor for the orders table.
A3 creates a composite table object, # indicating the composite table is ordered by oid. A4 appends data from the database cursor to the composite table.
A5 through A7 generate the details table in the same way. Note that the create function in A6 is affixed with the @p option because the association field oid in the subtable details is not unique. @p indicates the first field, oid, is a segmentation key, which prevents detail records for a single oid from being split during segmented reads.
With the data prepared, you can now use esProc to speed up EXISTS.
Problem 1: Count the number of orders containing pid 7 and within a specified date range, grouped by cid.
SQL code:
select o.cid, count(o.oid)
from orders o
where o.odate >= '2024-12-31'
and o.odate < '2025-01-01'
and exists
(select *
from details d
where d.oid = o.oid
and d.pid=7)
group by o.cid;
Even though the date range was only one day, MySQL took 114 seconds to execute.
esProc transforms EXISTS operations into primary-subtable joins:
A |
|
1 |
=file("orders.ctx").open().cursor@m(oid,cid;odate>=date(2025,12,31) && odate<date(2026,01,01)) |
2 |
=file("details.ctx").open().cursor(oid;quantity==7;A1) |
3 |
=A2.group@1(oid) |
4 |
=joinx(A1:o,oid;A3:d,oid) |
5 |
=A4.groups(o.cid;count(o.oid)) |
A1 and A2 conditionally filter the primary and sub tables.
A3 groups order detail records with pid 7 by oid, retaining only the first oid in each group. This avoids generating grouped subsets, improving performance. A4 then sequentially merges these results with the orders table, and A5 groups and counts the order quantity.
It’s important to note that the last parameter of the cursor in A2 is A1, indicating that for multi-threaded parallel processing, details will be segmented following orders to ensure the correctness of the subsequent ordered merge of the two tables.
Execution time: 0.8 seconds.
Problem 2: Count the number of order detail records with pid 6 that cannot be found in the orders table:
select count(d.oid)
from details d
where d.pid = 6
and not exists
(select *
from orders o
where o.oid = d.oid)
MYSQL ran for 9 minutes.
esProc code:
A |
|
1 |
=file("orders.ctx").open().cursor@m(oid) |
2 |
=file("details.ctx").open().cursor(oid;quantity==6;A1) |
3 |
=joinx@d(A2,oid;A1,oid) |
4 |
=A3.skip() |
In A3, the @d option of joinx means filtering the details table using the orders table, keeping only those records whose oid values do not exist in the orders table.
A4 counts the number of records in the cursor from A3, providing the desired result.
Execution time: 1 second.
Problem 3: Find orders with more than one detail item and that do not contain pid 9, and then group the orders by date and count the orders. SQL uses an EXISTS and a NOT EXISTS:
select
o.odate,
count(distinct o.oid)
from
orders o
where
exists (
select 1
from details d
where d.oid = o.oid
group by d.oid
having count(*) > 1
)
and not exists (
select 1
from details d
where d.oid = o.oid and d.pid = 9
)
MYSQL ran for 10 minutes without producing a result.
esProc code:
A |
|
1 |
=file("orders.ctx").open().cursor@m(oid,odate) |
2 |
=file("details.ctx").open().cursor(oid,pid;;A1) |
3 |
=A2.group(oid) |
4 |
=A3.select(~.count(oid)>1 && !~.pselect(pid==9)) |
5 |
=joinx(A1:o,oid;A4:d,oid) |
6 |
=A5.groups(o.odate;count(o.oid)) |
A3 groups the details table in order by oid.
A4 loops through each group, with ~ representing the current group. Only groups with more than one oid and not containing pid 9 are retained.
Execution time: 4 seconds.
Test results:
MYSQL |
esProc |
|
Computation 1 |
114 seconds |
0.8 seconds |
Computation 2 |
9 minutes |
1 second |
Computation 3 |
No results generated after 10 minutes |
4 seconds |
Using esProc to speed up EXISTS in primary-subtable joins exhibits very significant effects.
esProc’s speedup solution requires primary and sub tables to be stored in order by primary key oid. If there is new data, which is typically new oid values, you can append them directly to the existing composite table.
If historical data needs to be changed – for example, modified, inserted, or deleted – things become a little bit cumbersome. When the amount of changed data is small, esProc will write it to a separate supplementary area. During reading, the supplementary area and normal data are merged and computed together, resulting in a seamless experience.
When the amount of changed data is large, a full re-sort is needed to regenerate the ordered data. However, this process requires sorting, which is time-consuming and cannot be performed frequently.
In practice, numerous computational scenarios rely on static historical data, and many EXISTS operations in joins between large primary and sub tables urgently need performance improvements. SPL ordered storage can effectively speed up these scenarios, and implementation is remarkably straightforward.
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version