

Local Data Analysis: DuckDB or esProc SPL?
DuckDB can directly read common files such as CSV, Parquet, and JSON. With just a single SQL statement, it can load the file and perform a query, such as SELECT * FROM ‘data.csv’ WHERE price>100. For users accustomed to SQL, this “file-as-table” operation experience is very user-friendly, enabling rapid implementation of simple filtering and aggregation calculations.
However, when faced with complex scenarios—such as cross-file iterative calculations, processing unstructured logs, or implementing dynamic conditional branches—relying solely on SQL often falls short. In such cases, you have to resort to Python for writing loops or UDF. This hybrid programming approach leads to a noticeable sense of split: You need to constantly switch between SQL’s logical thinking and Python’s procedural thinking when programming, and separately handle SQL snippets and Python variables when debugging, which is quite cumbersome.
esProc SPL is a significantly better alternative. It supports over 20 file formats, including CSV and Excel, and can also parse semi-structured data such as RESTful and NoSQL, providing broader data source support than DuckDB. Moreover, esProc provides both SQL and SPL syntax, allowing you to use SQL for simple queries and SPL for complex tasks. All tasks can be handled within the same interface.
For example, when calculating the number of consecutive rising days for a stock, SPL can easily implement ordered grouping and this ability can be combined with SQL to accomplish this task:
A |
|
1 |
$select * from stock.csv order by trade_date |
2 |
=A1.group@i(close_price<close_price[-1]) |
3 |
=A2.max(~.len()) |
This concise syntax based on sequence numbers is more intuitive and easier to understand than SQL’s multi-layer nested subqueries.
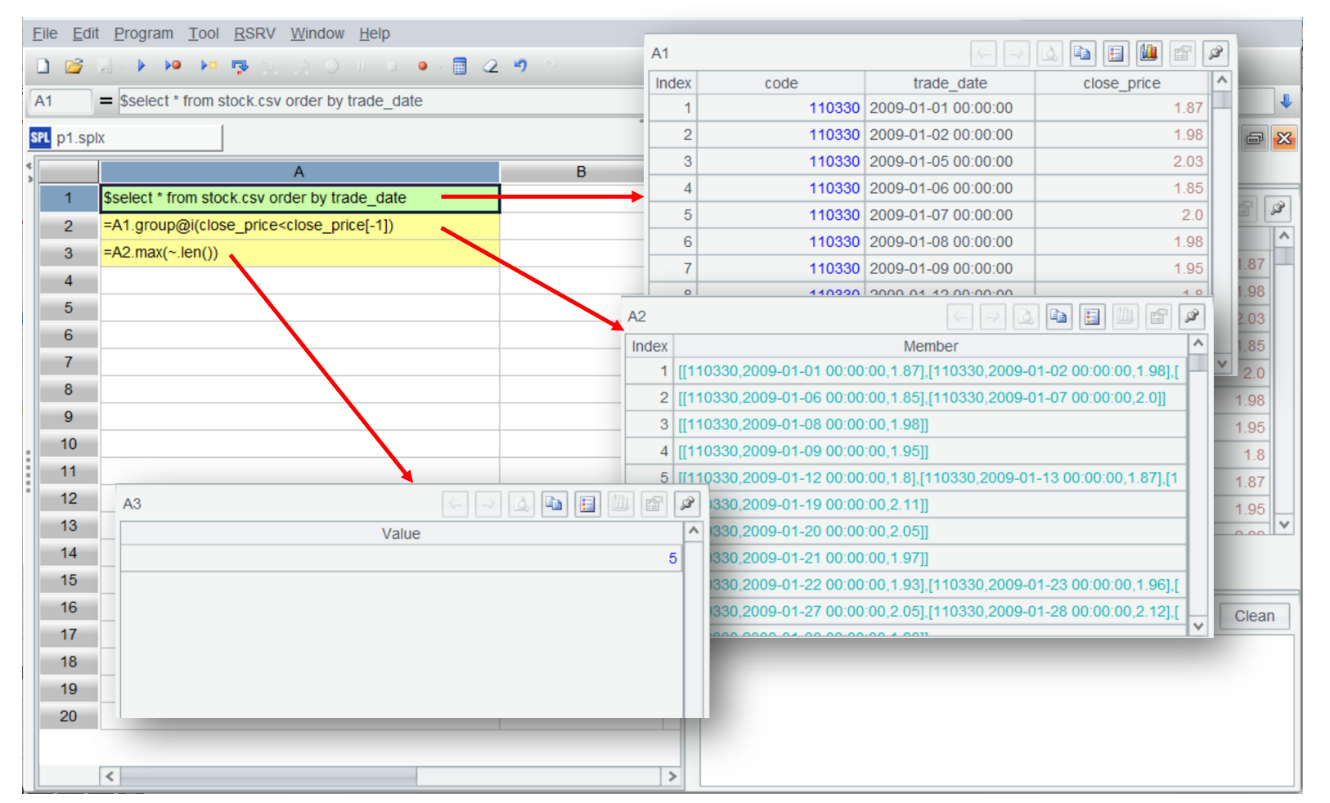
With esProc SPL’s IDE, developers can view the results of each step in real time, offering higher interactivity and far superior debugging efficiency than DuckDB, and it is also more intuitive than Python’s IDE.
With the support for diverse data sources and procedural computation, SPL fully covers the entire workflow from data loading to result output. For example, in e-commerce user behavior analysis, reading JSON logs, associating CSV product tables, calculating page dwell time, and generating funnel results can all be done with just a single script, without the need to switch interfaces.
If the amount of data is larger, SPL can utilize cursor and parallel processing to handle the data. Tests reveal that SPL’s multi-thread segmented loading technology is more than 3 times faster than DuckDB when performing grouping and aggregation on a 100GB CSV file.
DuckDB is suitable for simple SQL file query scenarios, while esProc SPL is more appropriate for complex calculations or big data processing. A system combines the simplicity of SQL, superior procedural computing capabilities than Python, and a more interactive IDE—truly an all-in-one tool.
SPL Official Website 👉 https://www.esproc.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.esproc.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/sxd59A8F2W
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version